
Googlebot FAQ
1. What types of Googlebot exist?
Google has several crawlers and fetchers. They are built for different services and purposes. For us, SEOs, the main interest is in two: Googlebot Smartphone and Googlebot Desktop.
Years ago, switching to mobile-first indexing was a hot topic, as it changed the crawl ratio between the two bots. However, nowadays it’s not so important, usually most websites are crawled mostly by the Smartphone bot.
2. How does Googlebot find new pages on a website?
The simple answer: By links on your website.
The primary task of Google is to answer users’ questions, and it continually needs to discover new pages with useful content. Links were, are, and will be the core principle of building websites. Googlebot understands pages not only by content but also in connection with other pages, their content, anchor texts, and other factors.
Sitemaps are also a source to find new pages on the website. But it is usually used as an additional source. For a big website, putting tens of thousands of URLs in sitemaps does not guarantee that Googlebot will crawl those pages. Internal links are way more important for this task.
3. What is two-stage rendering?
Modern technologies, like JavaScript, make the Googlebot’s job way harder. Ten years ago, it was sufficient to simply download the page’s HTML content, parse it, and analyze it. Nowadays, we have many websites that don’t have any content in pure HTML. Googlebot has to render them, which means executing JavaScript code. This is a very resourceful operation, and Google wants to optimize the cost.
First, Googlebot fetches the page as is, analyzes the content, and so on. Depending on many factors, it may or may not send the page to a second stage – JavaScript execution. After that, it will have the full content, which was/may have been added by JavaScript.
Usually, for small, especially high-traffic websites, it’s not an issue. However, for large websites, especially those with hundreds of thousands of pages, it becomes a crucial point. If the main content is present only after JS execution, it may lead to indexation delays, resulting in more days to get pages indexed and receive organic traffic.
4. Does Googlebot have any crawl path?
There are some speculations and myths, like Googlebot has some paths on how it crawls a website. Placing a link on a page to the same page itself may create a loop, and Googlebot will struggle. Googlebot is a pretty old application, and over the past 30 years, the dev team has seen and fixed such types of cases.
In contrast with SEO crawlers like JetOctopus, Googlebot has a different algorithm for crawling websites. First of all, the initial and the most basic factor is the amount of traffic to a page. If a page ranks, let’s say, in top 3 on a high-frequency query (car insurance) it will be recrawled every minute or even more frequently. Why? By sending a large number of visitors to a page, Google aims to ensure that the page still contains the necessary content and is relevant to the user’s intent.
Another important factor is that Google has its own ‘memory’ – index. It does not need to recrawl a website from the beginning. The indexed pages have priority to be recrawled by Googlebot. And that decision is made upon multiple different factors, like the frequency of content update.
5. Do Googlebot requests to JS, CSS, and images consume crawl budget?
No, those requests are usually made during the second stage of page rendering by Googlebot.
To analyze crawl budget properly, you need to exclude those requests. Otherwise, you may see ‘crawl budget growth’ where it’s not present.
6. Does Googlebot scroll a page?
No, it uses a different approach. Some sources said that it has a long viewport. Other than that, it has a virtually endless height viewport. In reality, as an SEO, you have to care to have all the needed content present on a page without any user interactions – clicks, scrolls.
For example, if after a page is opened, the first screen has content. But the rest is shown after the onScroll event – that’s not good.
Googlebot has many hacks, trying to get the JS page content as much as it can. But web developers are usually very talented and can introduce new ways to build pages. It’s always a good idea to test how Google sees the page content by searching for some pieces of a page’s content from different places in Google with site:url.
7. Does Googlebot see the hidden content?
If a CSS rule hides it, yes. The easiest way to check is to open the page source code by right-clicking ‘View page source’ (not a developer tool). If you can find the needed text in the pure HTML, Googlebot can as well.
In case a block of content is not present in the HTML but it loads after a click from the server, it will be not be visible to Googlebot.
8. Googlebot clicks on buttons?
No. Googlebot does not interact with a page as a user. However, visually it can be a button, but in the HTML it’s an <a> tag styled as a button. In this case, Googlebot sees a usual HTML link and will follow it.
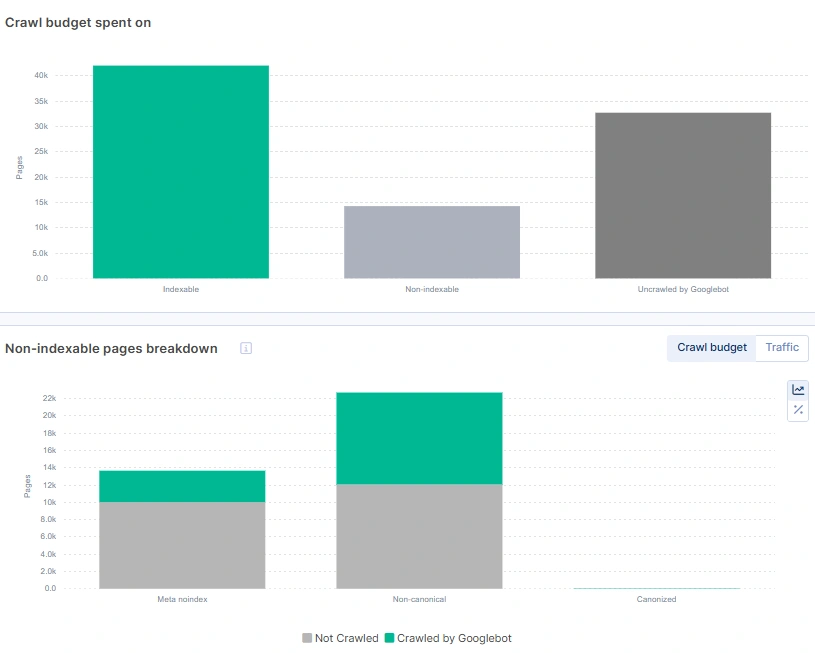
9. Do non-indexable pages consume crawl budget?
Yes, it’s a very common misconception that if you put a meta noindex tag, those pages will be de-indexed and will not consume the crawl budget.
How will Googlebot see the meta tag? It has to crawl a page and spend resources to analyze the page. After all, it has to recrawl again a non-indexable page just to check if the tag is still present or you decided to open the page for indexation again.
It becomes a huge issue for big websites that have dynamic indexation rules based on some factors, like product count on listing pages, product availability etc.
Non-indexable pages may waste as much crawl budget as is their share of all website pages.
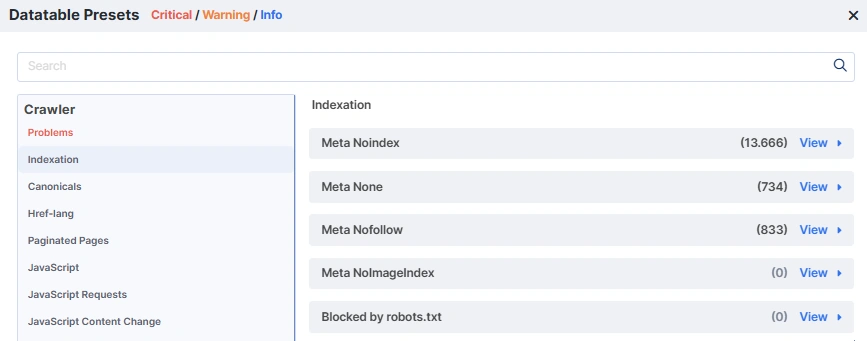
10. Meta noindex, follow
It was a popular way to not index some pages, but now Google states that nofollow attribute is a hint, so probably in some cases googlebot still might crawl the links on pages with meta noindex. Based on our experience and data the method (only) is not working nowadays.
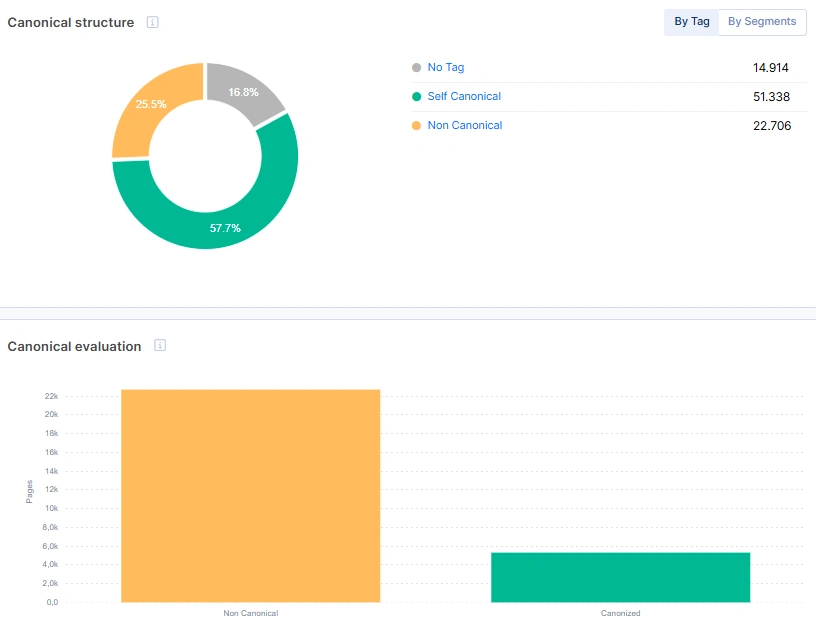
11. What’s the problem with non-canonical pages?
In contrast to the meta no-index, the non-canonical directive is a hint to Google. It may be followed, or it may not. The primary issue is its misuse.
Very often, on e-commerce websites, the PLPs with filters, combinations, sorting and pagination simply have a canonical tag pointing to the root listing page. From Google’s perspective, it has to analyze the page, compare the content with the root page, and decide whether it’s similar or not, and then decide whether it’s canonical or not. The faceted filter combinations can easily produce millions of pages. Will Googlebot crawl all of them? No.
It simply will use pattern matching and stop crawling such types of pages. The problem is when the URL pattern contains valuable pages, or when you need to index some faceted filters combination, like color, brand or size. As a result, wasted crawl budget, problems with indexation, and low organic traffic to long-tail keyword pages.
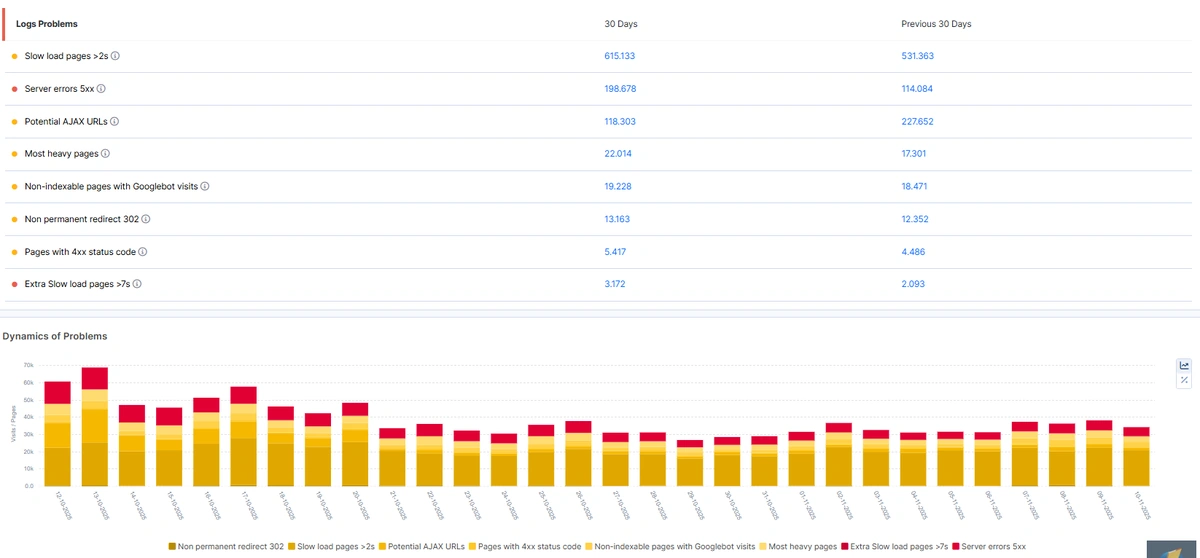
12. Do site errors and speed influence Googlebot behavior?
Yes, and a lot! When Googlebot receives 429 and 5xx status codes, it reduces the crawl ratio. When a website experiences technical issues, the server actually must return a 5xx status code. It’s normal, sometimes websites are down. Also don’t forget to never use a 200 status code for maintenance pages.
Load time is another significant factor, especially when it degrades. In the eyes of Googlebot, it appears that a website is overloaded, so the bot slows down its crawling, resulting in a reduced crawl budget.
13. Increasing/Declining crawl budget: Is it good or bad?
It always depends on how fast the changes are. Crawl budget is never a stable number. The number of requests fluctuates daily.
If you see a two-to-three-times-daily spike in requests from Google, it’s definitely a reason to take a closer look. A website may generate some trashy pages, and Googlebot is happy to crawl and index them. It will lead to a massive headaches after cleaning them from the index.
If there is a week spike, it could be an update of Chrome version inside Googlebot. Very often it recrawls websites after the release.
It’s essential to monitor the crawl budget daily, particularly after updates to a website. You can spot the issues earlier and take the necessary actions to prevent damage to your website’s index as soon as they appear.
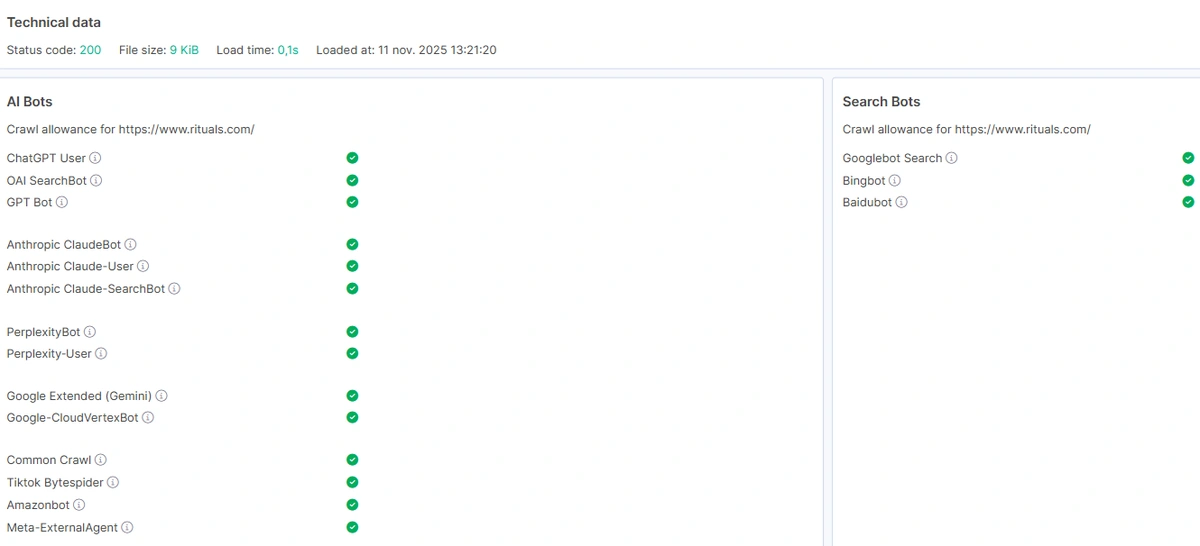
14. Can Googlebot ignore robots.txt rules?
No. Sometimes, robots.txt is not actually a stored file but is generated dynamically for every request. In all cases, when we saw ‘ignoring robots.txt’, it was actually problems with the robots.txt file. Googlebot fetches it many times per day, and when it doesn’t work, the bot decides, ‘I can crawl everything!’
15. Why is the page indexed while blocked in robots.txt
Robots.txt is a way to manage Googlebot crawling files, but not pages indexation.
If a blocked page has tons of internal links, some backlinks, Google can see the anchor text to it, and the nearby texts. By considering all these factors, even without viewing the page content, Google can index and rank a page.
If some pages are particularly great, it might be a good idea to exclude them from robots.txt.
This type of issues is quite common on e-commerce websites: tens of thousands of pages may be indexed, staying blocked in robots.txt. In this case, the solution is to remove direct links to them, use JavaScript techniques to navigate to those pages and block them from indexation with meta noindex.
About Serge Bezborodov
Serge is the co-founder and CTO of JetOctopus, a tech SEO expert and log-file analysis enthusiast with over a decade of programming experience. A passionate advocate for data-driven SEO, he regularly shares insights from billions of crawled pages and analyzed log lines, helping SEOs turn complex data into actionable strategies.You can find Serge on Twitter and LinkedIn.
