
Crawling big e-commerce websitess
Technical SEO for large e-commerce websites is one of the most challenging and rewarding areas in search marketing. You’re working with millions of URLs, historical issues, technical debt, and unexpected surprises, sometimes all at once.
Crawling isn’t a “nice-to-have” in this environment. It’s a foundational activity that helps uncover deep technical problems and build a strategy for improvement.
In this article, I’ll walk you through practical strategies and real-world advice on how to effectively crawl enterprise-scale e-commerce websites.
Crawl Objectives and Scenarios
Before touching a single setting, define the goal of your crawl. Without a clear objective, you risk wasting time, overloading servers, or gathering irrelevant data.
Most crawls fall into one of three categories:
- Full snapshot crawls. Capture a full picture of the entire site. Ideal for internal linking audits, technical health checks, and benchmarking before a migration.
- Partial/sectional crawls. Focus on specific directories, templates, or problematic areas (e.g. /sale/, PDPs, or faceted pages).
- Ad hoc test crawls. Useful for quick validations, troubleshooting, or testing custom extractions before launching a full crawl.
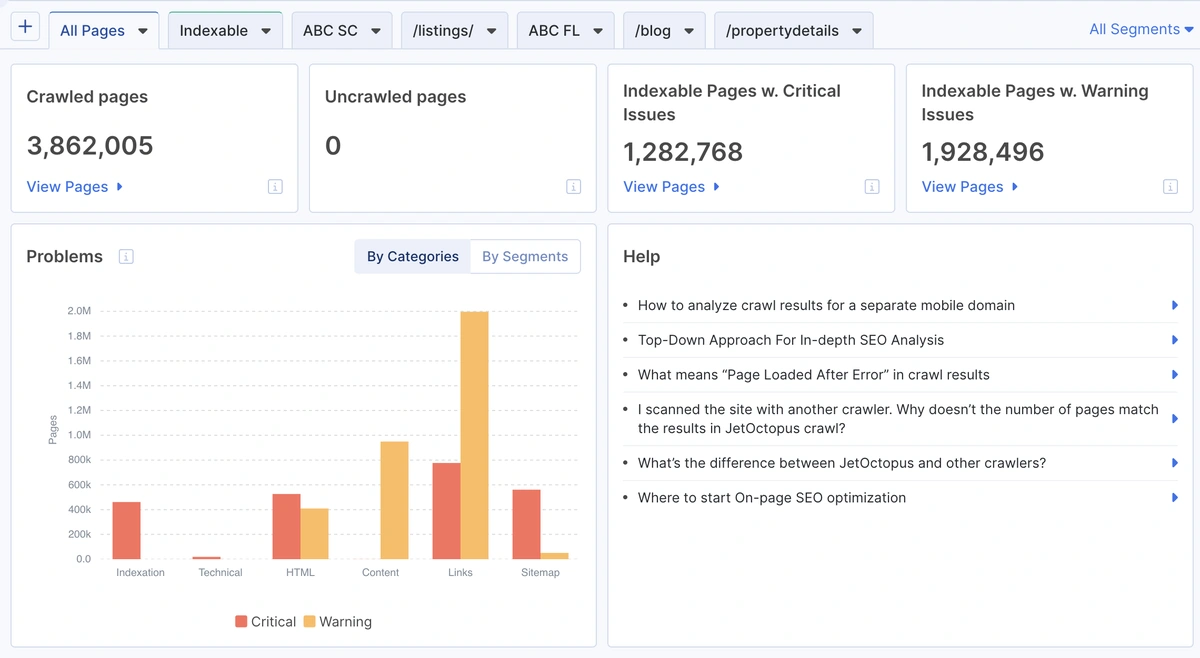
🧭 Full snapshot crawl across category structure.
Even though no pages were skipped, nearly 2 million indexable pages showed critical or warning-level issues — highlighting why deep, site-wide crawls matter for technical SEO visibility.
Match your crawl type to your analytical goal to avoid overkill, or worse, missing important signals.
Full Crawl vs. Partial Crawl
When we talk about mid-sized websites with around 5-10 million pages, it’s essential to run a full crawl at least a few times per year.
A full crawl gives you a comprehensive snapshot of the website’s current state, especially the internal linking structure. Without this, you may miss systemic issues hidden deep within the site.
In contrast, a partial crawl typically covers only the top-level pages closer to the homepage. Pages deeper in the structure may remain uncrawled, giving a distorted or incomplete view of the site’s true condition.
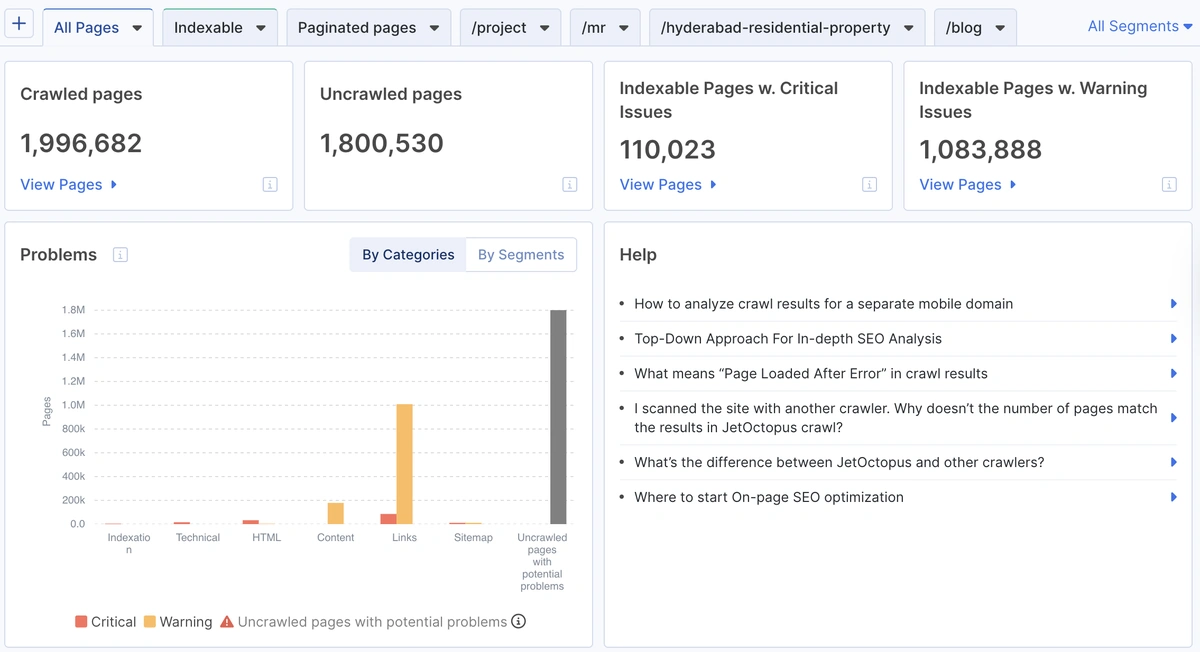
📊 Partial crawl result showing limited depth coverage.
Even though nearly 2 million pages were found, over 1.8 million weren’t crawled — a typical outcome when relying on paginated or filtered views only.
For colossal websites, those with 20-50 million or more pages, the situation becomes more complex. Unless the infrastructure can handle 500 or more crawl requests per second (on top of regular user and bot traffic), completing a full crawl becomes almost impossible.
We’ve handled cases like this, but only with full support from DevOps teams who allowed us to process up to 1,000 requests per second. The servers were running red hot.
In most real-world scenarios, the solution is to crawl the first 3, 5, or 10 million pages, then analyze in more depth the subdirectories that raise concerns. This approach gives you focused insight without overwhelming infrastructure or waiting months for crawl results.
Crawl Speed and Resource Planning
Any crawl should be completed within a meaningful timeframe. It might take days, weeks, or even months, but running a crawl for half a year? That’s rarely useful.
Why? Because websites change. Products go out of stock. Pages are updated, removed, or redirected. Catalogs shift. By the time you’ve finished crawling millions of pages, a large portion of that data may already be outdated.
How to Calculate Crawl Duration
Let’s say you need to crawl 1 million pages. Each page takes about 1.5 seconds to load, and your DevOps team allows you to run 5 simultaneous threads:
1,000,000 × 1.5 seconds ÷ 5 = 300,000 seconds = ~84 hours (~3.5 days)
Now consider a site with 15 million pages and a load time of 2 seconds per page:
15,000,000 × 2 ÷ 5 = 6,000,000 seconds = ~1,667 hours (~2 months)
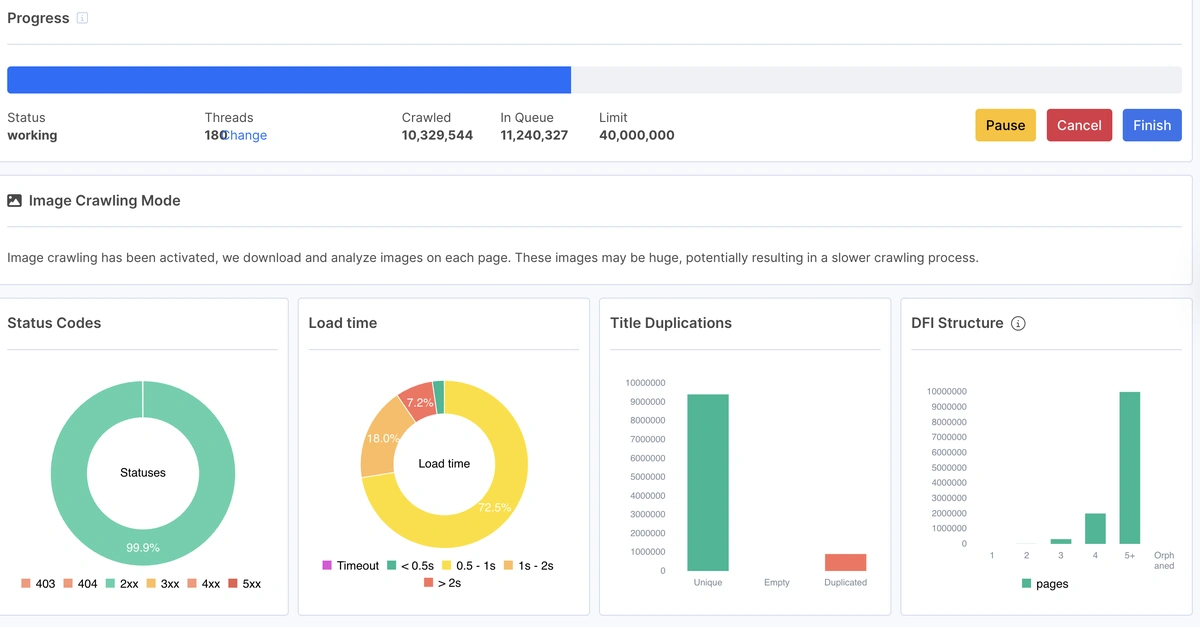
📈 Real-Time Crawl Metrics Dashboard
This screenshot provides a real-time snapshot of crawl performance. It shows active thread count, the number of pages already crawled, and those still in the queue — critical data for estimating total crawl time. Additional charts reveal page status codes, load time distribution, duplicate titles, and DFI (Distance From Index) structure. Together, these metrics help diagnose crawl efficiency and spot structural or content-related issues early on.
Clearly, that’s not practical. One solution is to increase the number of threads, say, to 20. That reduces the crawl time to around 18 days. However, increasing thread count may put strain on the site’s infrastructure and risk performance issues.
If your DevOps team limits you to just one thread per second, things get even more challenging.
In this case, proactive communication becomes essential. Help stakeholders understand why technical SEO and crawling matter. But keep in mind, this kind of buy-in takes time.
Another strategy is to schedule your crawl during low-traffic hours. Early mornings or late nights are often safer windows where more threads can run without affecting site performance. JetOctopus, for example, supports custom crawl scheduling to adapt to traffic patterns.
It’s also critical to give the DevOps team visibility and control over the crawl. Make sure they can pause or resume the crawl if needed. Otherwise, they might block your crawler entirely, and you’ll end up with thousands of 403 status codes in your data.
Making friends with your DevOps and infrastructure teams is always a smart move. A smooth crawl depends on their support. your SEO performance without involving legal or security teams to review personal data concerns.
Custom crawl rules, allow/disallow directories, URL patterns
Ideally, there should be no custom crawling rules, instead follow the robots.txt rules. Why? If you need those rules to crawl your website, why don’t you put them in robots.txt? Why should Googlebot crawl those pages?
That said, editing robots.txt is often politically or technically risky, especially on enterprise teams. So SEOs fall back on custom crawl rules to exclude problematic areas.
Every website has its own specifics, and there’s no one-size-fits-all rule. But generally, your crawl configuration should pay close attention to:
- Faceted navigation URLs (filters by size, color, etc.)
- Sorting and pagination parameters
- Internal search pages
🧩 Example of custom crawl rules configured to exclude unwanted URLs such as refinement filters or redirect partners. These rules help streamline the crawl by avoiding irrelevant or duplicative content.
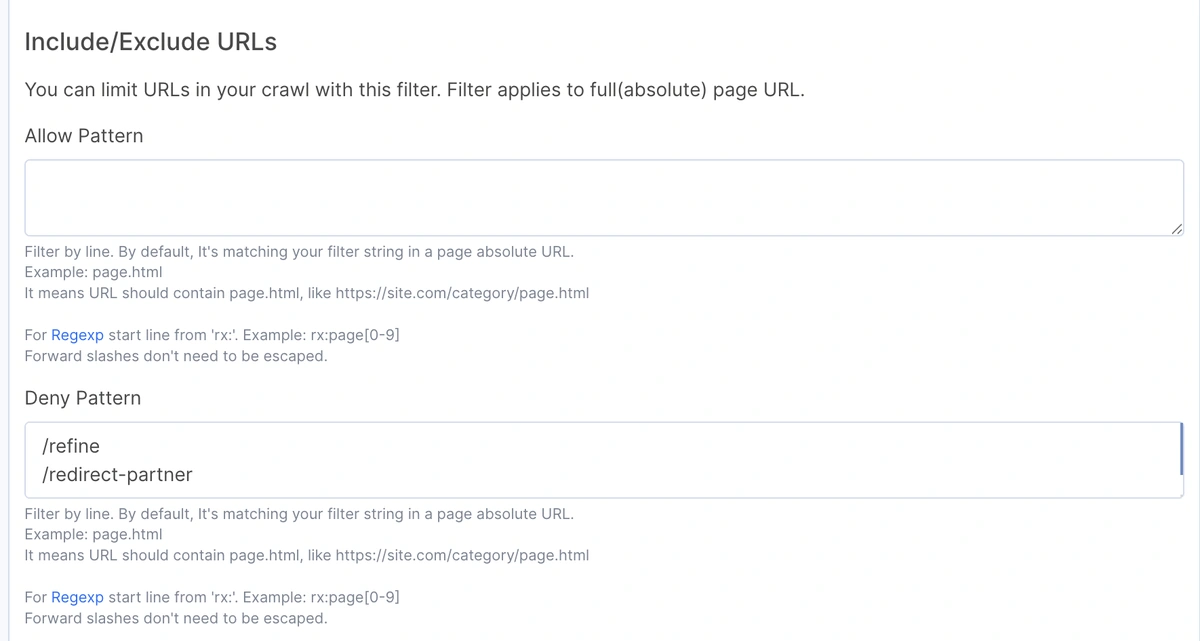
If a filter generates thousands of near-duplicate URLs, it’s often best to exclude those patterns using allow/disallow rules or regex filters within your crawler. This not only reduces crawl time but also focuses the analysis on SEO-relevant pages.
These areas are also where crawl budget is often wasted. Pages with endless variations can drain Googlebot resources with little SEO return. Flag them early, they’re almost always the holes in crawl budget inefficiency, and you’ll need to revisit them during log analysis.
Custom Extraction Rules
This is where a crawl becomes truly insightful. E-commerce pages aren’t just HTML, they’re dynamic product catalogs. Custom extraction lets you pull important commercial and structural signals directly from pages.
Extract from Product Listing Pages (PLPs):
- Number of products displayed
- Number of pagination pages
- Presence and quantity of internal link blocks (e.g. cross-links or filters)
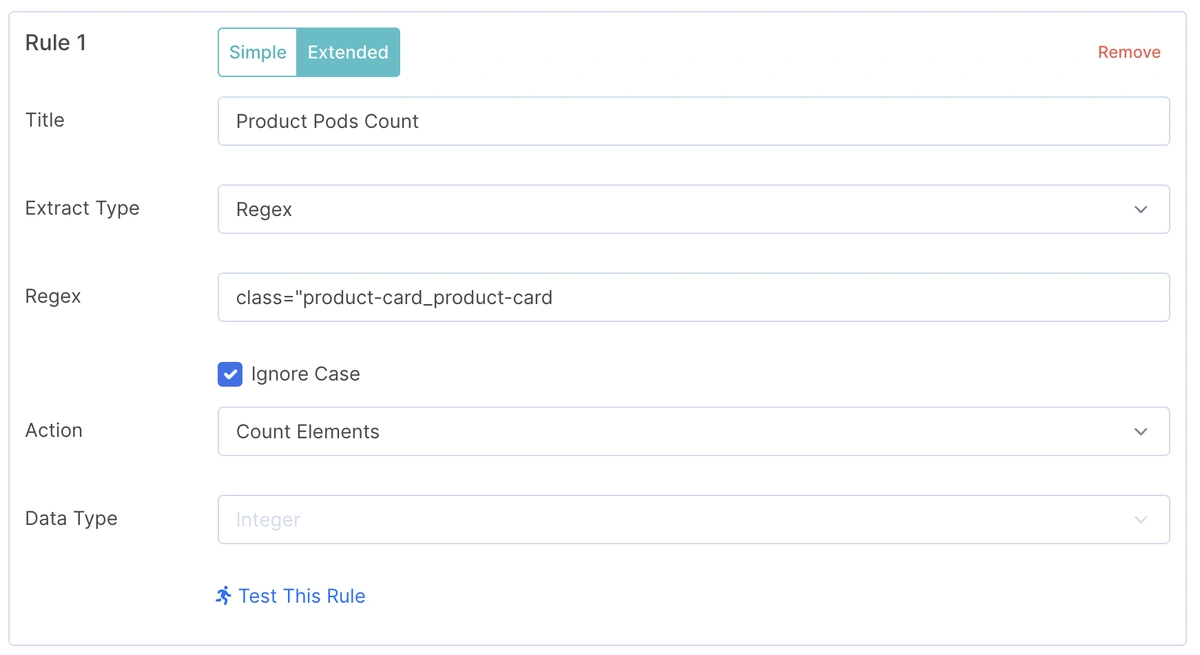
📌 Example of extracting product count from a listing page. This helps evaluate page depth and inventory visibility.
Extract from Product Detail Pages (PDPs):
- Availability (e.g. in stock / out of stock)
- Price
- Product description
- User-generated content (reviews, Q&A)
- Internal links to related products or categories
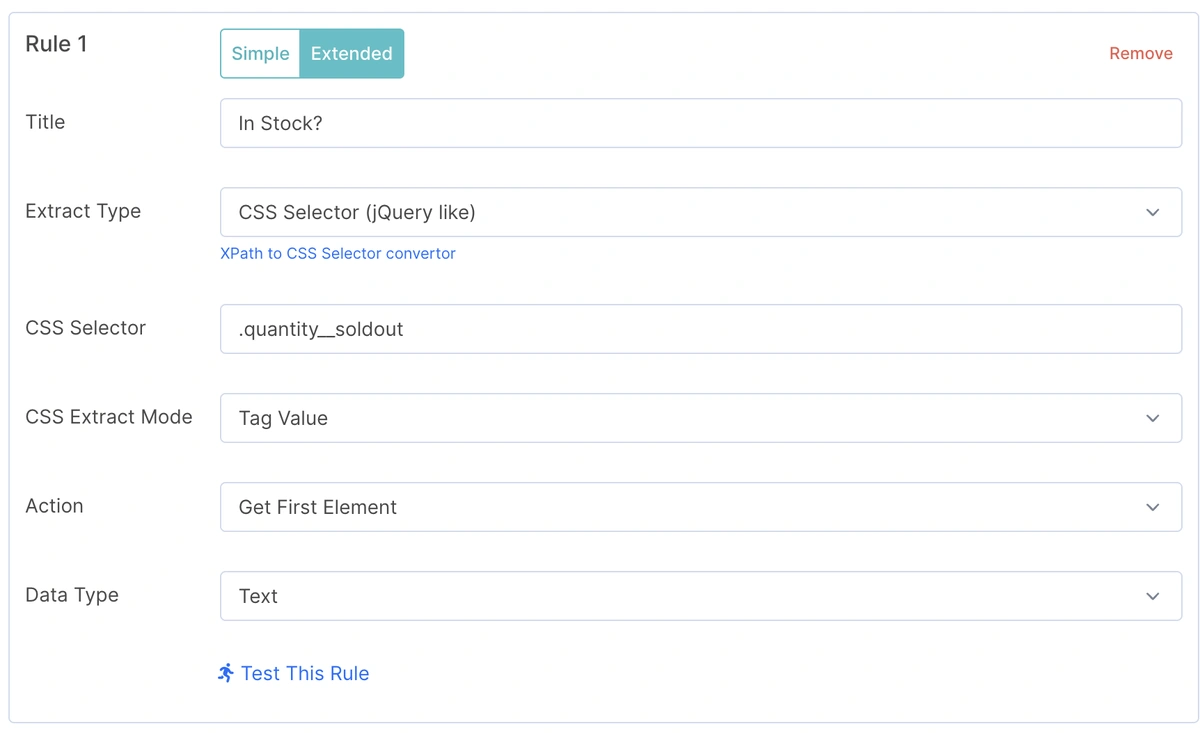
📌 Custom extraction rule for stock availability on product pages — essential for identifying low-value or out-of-stock URLs.
These fields become critical when analyzing:
- Crawl budget waste on out-of-stock or low-value pages
- Thin PLPs (e.g. pages with 3 or fewer products)
- Internal linking effectiveness for key product sets
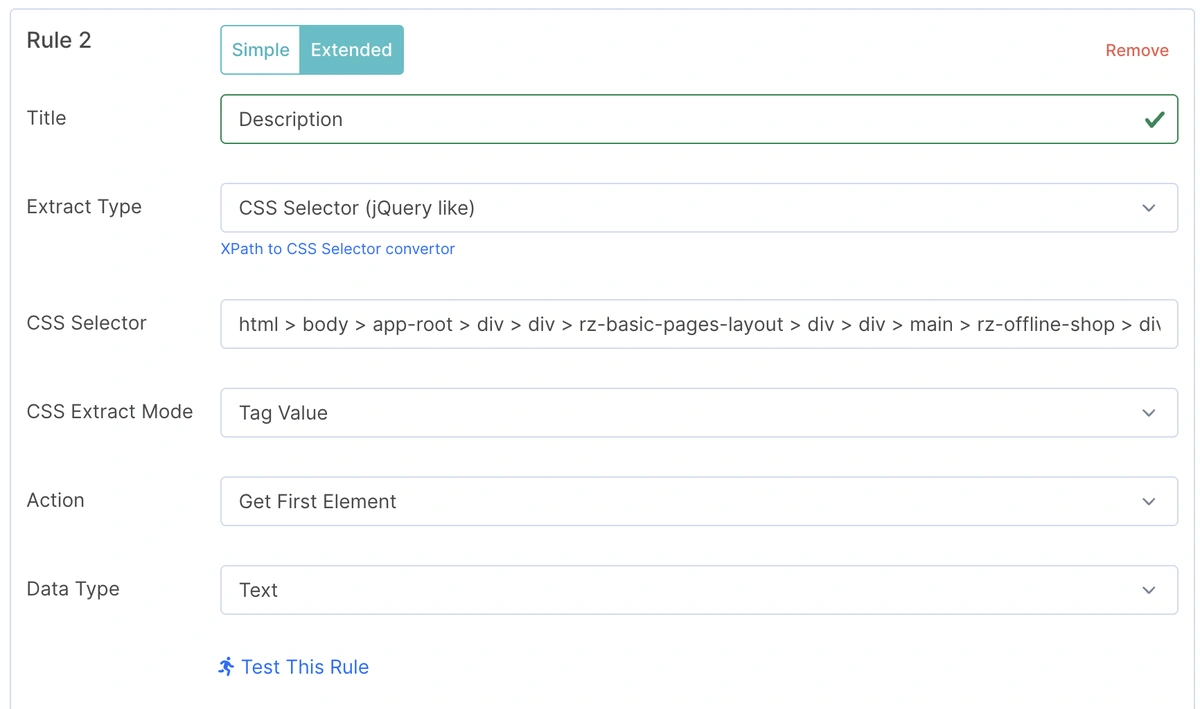
📌 Example of extracting product descriptions using a custom CSS selector — crucial for assessing page quality and user relevance.
Don’t just crawl metadata, pull what actually matters to both bots and users.el details from GA or GSC are accessed or stored.
Always Test Your Crawl Configuration
This is a step many skip and regret. Even if you’ve used a custom extraction rule before, run a small test crawl (10k-50k URLs) to confirm it works with the current site structure.
I’ve seen crawls run for weeks only to realize the extractor missed prices or availability fields due to a template update.
Final Takeaways
Before launching any crawl, ask yourself: “What exactly am I trying to uncover or prove?”
If your goal is just to find missing titles or 404 links, you don’t need a massive, complex setup.
But when you’re analyzing site structure, crawl budget allocation, internal linking depth, or indexation signals on a site with millions of URLs, your crawl configuration becomes mission-critical. It’s not just about collecting data, it’s about collecting the right data.
Invest the time to get it right.
About Serge Bezborodov
Serge is the co-founder and CTO of JetOctopus, a tech SEO expert and log-file analysis enthusiast with over a decade of programming experience. A passionate advocate for data-driven SEO, he regularly shares insights from billions of crawled pages and analyzed log lines, helping SEOs turn complex data into actionable strategies.You can find Serge on Twitter and LinkedIn.
