SEO for AI Search in 2026: Technical & Content Strategies That Actually Work

Work with Rel=canonical Like a Pro
Canonical tags were created to fix duplicate content issues. In a nutshell, if you have 3 duplicate pages (or approximately similar ones) you should pick just one of them to be shown in Google. Canonicalization is a way to help Googlebot decide what page to show in the SERP. However, rel=canonical tags don’t help the search engines unless you use them properly. This tutorial walks you through how you can use JetOctopus to audit rel=canonical tags quickly and efficiently across a website.
How to find non-canonical pages which are blocked from indexation
Google guidelines tell us that if the page is non-canonical, (rel=canonical tag points to the other page), this page should be open to indexation. It’s a common situation when rel=canonical tag is added to all pages indiscriminately whether these pages are open to indexation or not. This is an easy way how to find those pages with JetOctopus:
- If the crawler finds the above-mentioned problem, you will see the Non-canonical page is not allowed for indexation notification in the Indexation/Problems section. Once you click on the number of pages in this section, you get to the DataTable with the list of problematic URLs. You can export data in Excel or CVS format.
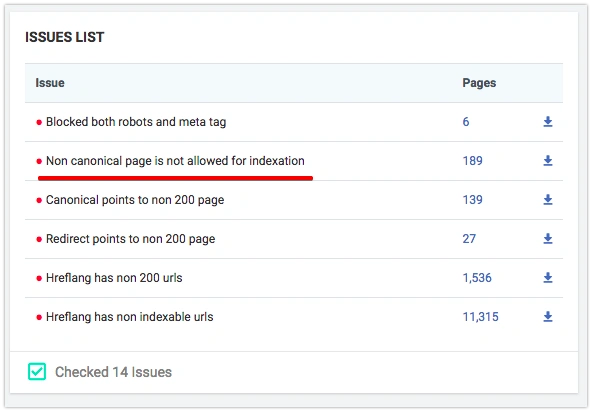
2. Choose filters in DataTable:
- Is Canonical Page = No
- Status Code = 200
- Is Meta tag Indexable = No
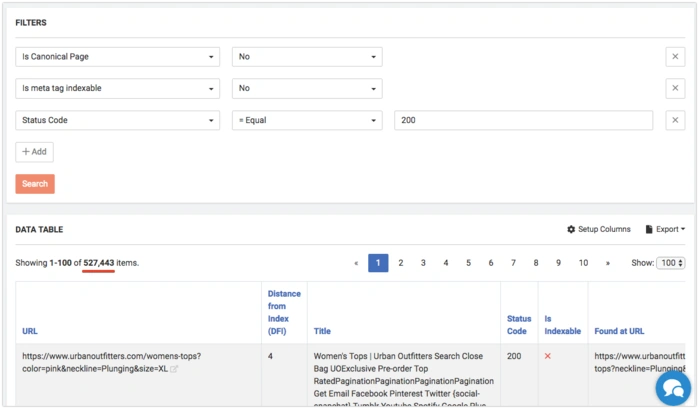
How to find self-canonical pages
Adding rel=canonical with URL that is equal to URL of the current page is a good practice that helps to avoid accidental duplicate pages issue. You should remember that self canonical page shouldn’t be closed with meta=robots noindex. Here is a way how to find self-canonical pages which are blocked by meta:
Choose filters in DataTable:
- Status Code = 200
- Is Self Canonical = Yes
- Is Meta tag Indexable = No
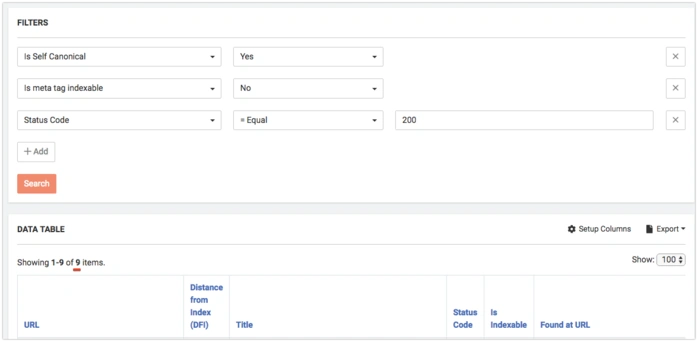
How to find all canonized pages
The canonized page is a page on which rel=canonical tags from other pages are pointed. It’s crucial for a canonized page to have 200 Status Code, be allowed for indexation and not to canonize the other page.
Find all canonized pages in DataTable. Set filter Is Canonized Page = Yes
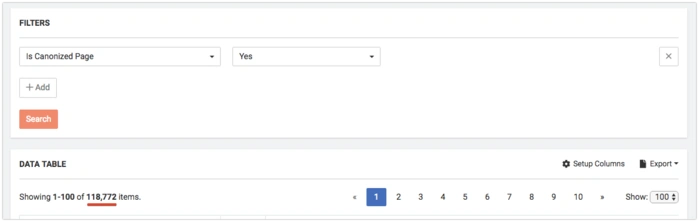
Then you can filter these pages to meet your individual requirements.
- Status Code=!NotEqual 200 – shows pages with all Status Codes except 200, so there can be different redirects, 404, 500 errors.
- Is Canonical Page = No – shows non-canonized pages or in other words canonical chains
- Is Meta Tag Indexable = No – shows pages that are blocked for indexation by meta tag.
Above mentioned cases are usually treated as bugs in Technical SEO and must be fixed.
How to find non-canonical pages which canonize blocked for indexation pages
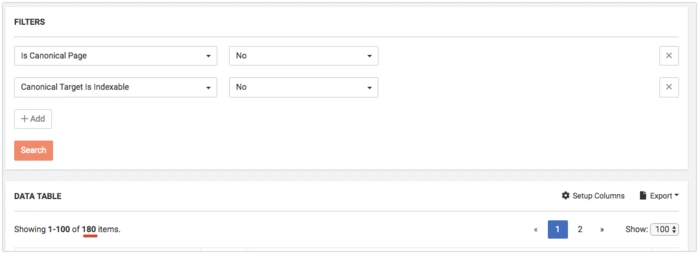
Canonized pages must be always opened for indexation. You can use abovementioned How to find all canonized pages method to find these pages or choose the next filters in DataTable:
- Is Canonical Page = No
- Canonical Target is Indexable = No
How to find non-canonical pages which canonize pages with not-OK 200 Status Code
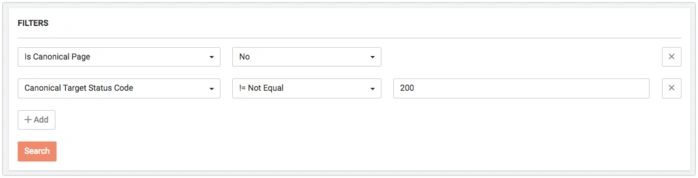
Canonized pages must have 200 Status Code response. To see canonized pages with other Status Codes, choose the following filters:
- Is Canonical Page = No
- Canonical Target Status Code != 200
How to find pages on which a majority of non-canonical pages point (the most canonized pages)
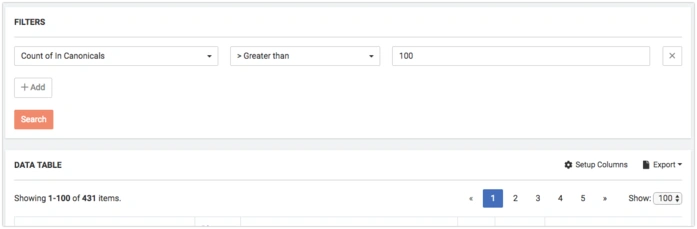
You can filter pages by values in DataTable, for instance:
- filter Count of In Canonicals > 100
- filter Count of In Canonicals = 1
Canonization has something in common with link building: page A can be canonized only with one non-canonical page, but page B – 100k different pages. This is a widespread situation on e-commerce websites.
Also, with the help of Setup Column you can add In Canonicals column
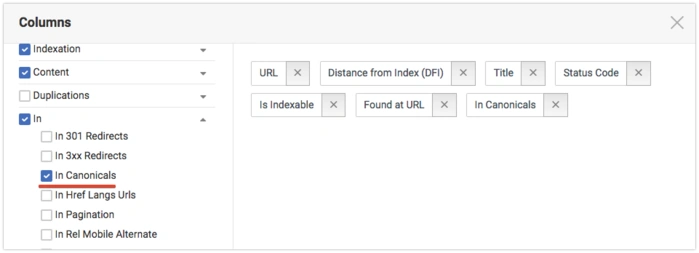
And sort pages by this column:
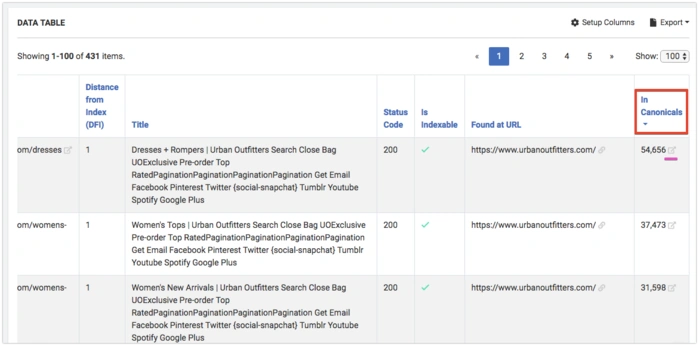
Where you can see all pages which canonized the selected page.
Further optimization
Wrong rel=canonical implementation can lead to huge SEO issues. We have a client-oriented philosophy, so if you have any questions about technical SEO in general, and the rel=canonical tags in particular, feel free to drop us a line jetoctopus-technical chat
Read more: Why Partial Technical Analysis Harms Your Website.
- Category:
- How to guides
- On-page Tech SEO
About Serge Bezborodov
Serge is the co-founder and CTO of JetOctopus, a tech SEO expert and log-file analysis enthusiast with over a decade of programming experience. A passionate advocate for data-driven SEO, he regularly shares insights from billions of crawled pages and analyzed log lines, helping SEOs turn complex data into actionable strategies.You can find Serge on Twitter and LinkedIn.

