
You probably know log files are treasure troves. You can see how bots crawl your pages, which content is frequently visited, or vice-versa, ignored by bots. But often SEOs don’t know how to get the value of logs – it’s time-consuming to explore the sheer volume of data manually, and analytics tools may be costly. Still, you need to find a way to extract the data from your logs. Today we’re going to demonstrate how log files analysis helps to reveal tag-related problems, indexability issues, and crawl budget waste.
We will cover:
- Are you sure you’re sending correct directives?
- AJAX. What content is better to hide?
- Canonicalization. Why rel=tag is not the best solution
Robots.txt. Are you sure you’re sending correct directives?
The path value in robots.txt is used as a basis to determine whether or not a rule applies to a specific URL on a site. In the case of conflicting rules, the least restrictive rule is used. Here is the case study when an incorrect order of precedence in robots.txt opened access to duplicated content.
About the website:
- Marketplace
- 226K pages
- 4M monthly visits
The website contains a number of filters, like prices, sizes, brands, etc. The content on those pages is similar, which is why search bots won’t show it in the SERPs. In order not to waste the crawl budget on duplicated pages, the webmasters closed these URLs in robots.txt. Nevertheless, for some unknown reasons duplicate pages were still in Google’s index.
What was done?
1. We crawled the website completely and filtered pages that were blocked by robots.txt.
There were no category pages on this list.
2. We analyzed the log files to see how the bots process duplicated pages. For some reason, the bot ignored disallow directives. We needed to understand WHY.
Our recommendation:
To check the robots.txt file with a Validator tool to verify that URLs have been blocked properly. Result: URL paths to products were allowed.

1. /*? in a Disallow field means “Block bots from accessing any URL that has ? in it” 2. Allow: /product means “Crawl all URLs which begin with product combination of symbols”. But the problem is the URL paths contain both variants.

Thus, directives contradict each other. Which rule does Googlebot respect? Let’s look at Google’s Robots.txt Specifications:

So, a number of duplicated URL parameters were crawled.
Key takeaway
Before submitting your directives, learn robots.txt guidelines for EACH search engine, because specifications can vary. Always use a robots.txt tester tool that shows you whether your directives block search engine bots from specific URLs on your site.
If you want to dive deeper into this topic, here are the most common robots.txt mistakes & ways to avoid them.
AJAX. What content is better to hide?
AJAX allows web pages to be updated asynchronously by exchanging data with a web server. This means it’s possible to load parts of a web page without reloading the whole page. Despite the fact that Google engineers have significantly improved rendering of JavaScript for the Googlebot, AJAX has a bad SEO reputation. Here is a case where Googlebot wasted 62% of the crawl budget on non-profitable AJAX content.
About the website:
- Real-estate website
- 1M+ pages
- 4.5M monthly visits
On the one hand, websites that use AJAX load faster and thus provide a better UX. On the other hand, these websites can be difficult for the search bot to crawl.
From the stage at the 2019 Google I/O event Googlers announced that now search engine bots are able to render and index client-side AJAX-style JavaScript POST requests. But be aware that other crawlers still don’t support this feature. Furthermore, when Google renders dynamic content driven by the XHR POST request method, each additional sub-request will count against your crawl budget. The content from the POST event isn’t cached as part of the page, and therefore crawl budget is reduced by the number of XHR requests.
We analyzed log files to see where the crawl budget was spent. Logs showed that Googlebot sent 38M requests during the month. 23.5M (!) requests were wasted on AJAX content.
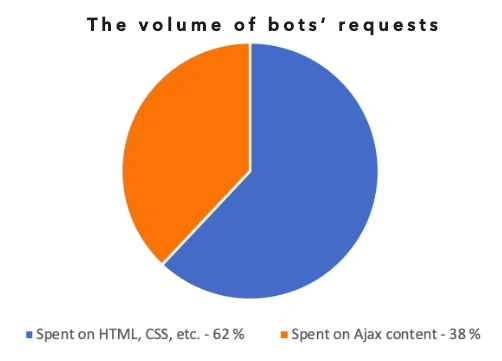
Our recommendation:
Check content that is provided on AJAX and evaluate whether it is worth being shown in the SERPs. Close content that provides no value in robots.txt for Googlebot.
Key takeaway
Before closing AJAX content in robots.txt, consider carefully what content is there. You can accidentally block the part of your webpage and the content can become meaningless for bots.
Canonicalization. Why rel=tag is not the best solution.
Rel=canonical tag is the most frequently used way to show Googlebot original/duplicated pages and the correlation between them. Does it mean that you should use this tag on your website? We answer, “It depends.” Here is a true story about how rel=canonical structure consumed crawl budget on e-commerce website.
- Jewelry online shop
- 16+M pages
- 342K monthly visits
One part of the website was in the SERPs and took TOP organic positions, while the other wasn’t in the index. We aren’t talking about outdated or user credentials content, but about relevant and profitable pages that weren’t indexed for months.
What was done?
1. JetOctopus started the crawl and analyzed 2M pages.
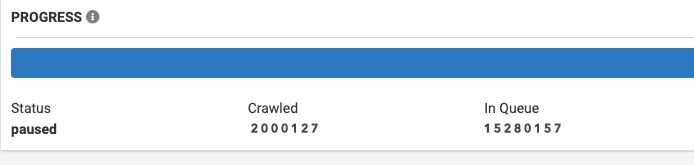
2. We found almost 900 internal links on each crawled page and calculated that there were around 16M (!) pages in total. We decided to pause the crawl to figure out why the website is so huge.
3. Log files were analyzed to see how bots crawled the website, and where the crawl budget was spent. We found out that Googlebot was spending resources on pages with rel=canonical tags. The thing is that webmasters inserted the canonical/self-canonical tag on each item in each category, filter, and also on each paginated page.
What recommendation we gave:
To close combinations of category+filter+pagination+sort that all together generated a bunch of pages. Result: Website size decreased to 730K pages so that search bot could crawl the most profitable pages.
Key takeaway
Robots.txt is not a universal solution. Yes, instead of blocking pages in robots.txt, Google recommends closing pages with ‘noindex’ tag. The problem is that on big ecommerce websites the bot still spends crawl budget while accessing the page code and finding directives. On the other hand, robots.txt can ask bots not to crawl some categories at all. So that crawl budget will be used on different profitable pages, not on few huge categories.
To sum up
Log files give you unique insights about what is wrong on your website, and where your SEO opportunities are. Whatever technical updates you conduct on your website, logs can show you how search bots perceive changes. Thus you can start fixing problems based on real data, not on hypothesis. Why not try it, especially since log analysis can be much simpler and more affordable than you might think!
Wanna learn more? How to migrate a site without SEO drop. Case study
















