
Thin pages. URLs with low text/HTML ratio. How and Why to detect them?
Search engines are not humans, and in order to understand whether the content on the page is valuable or not, they use algorithms. Pages with low textual volume and thin pages are usually considered by search engines as low-quality ones, unable to satisfy user intent.
Thus, for the sake of not losing website authority in the search engines` “eyes” and performing well in SERPs, we need to make sure all our pages provide visitors with quality content. And get rid of those pilling us back. Let`s have a look at them.
Thin pages
Why
A thin page is a page that contains less than 100 words. Neither Bot nor users like the thin pages because they waste time and effort on it but don’t get enough value.
The best solution would be to add relevant content that will be useful and interesting for your users. If you can’t enrich these pages, try to merge them by similar topics into one quality piece of content.
But first, you should detect thin pages.
How
1. Open Crawl – Content – Thin pages
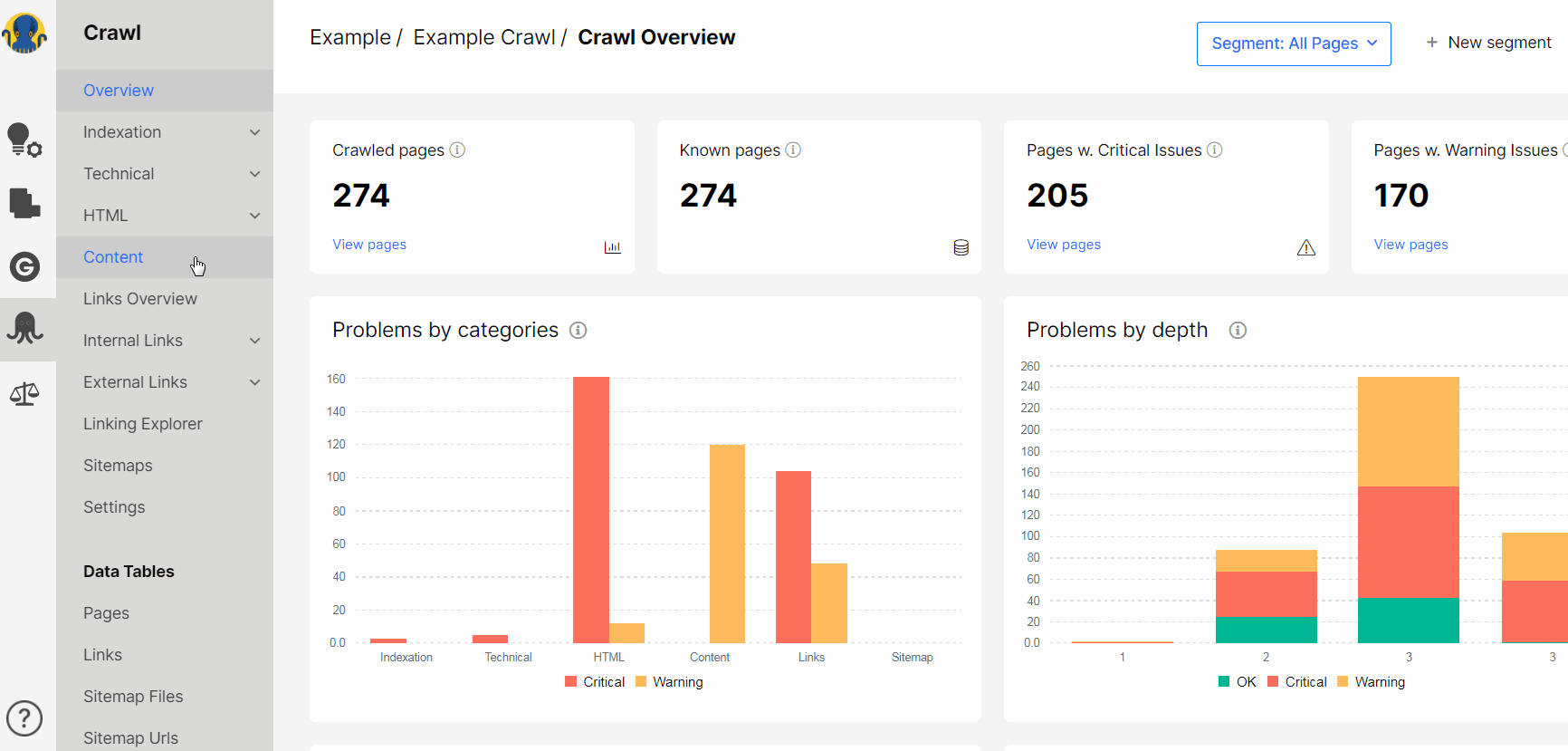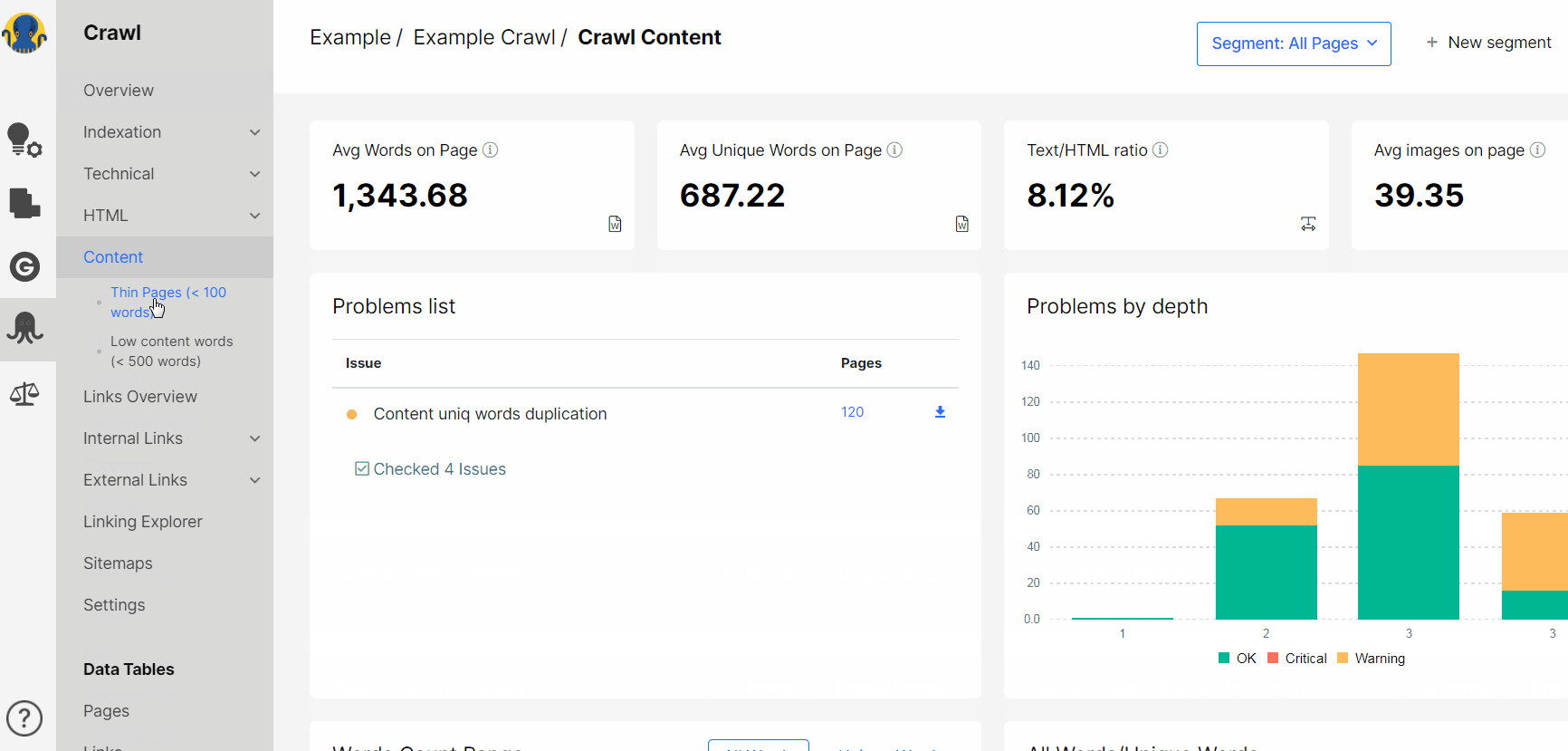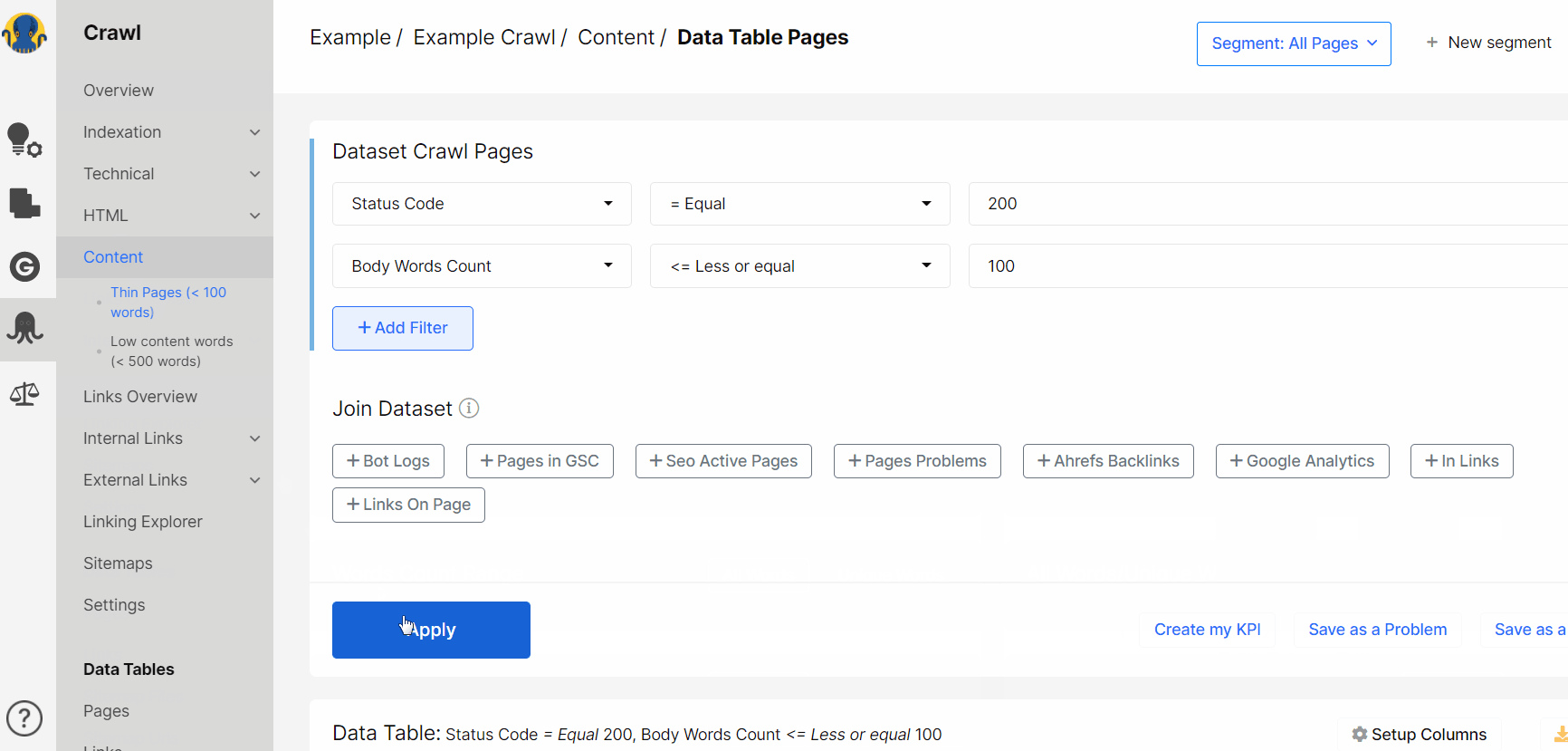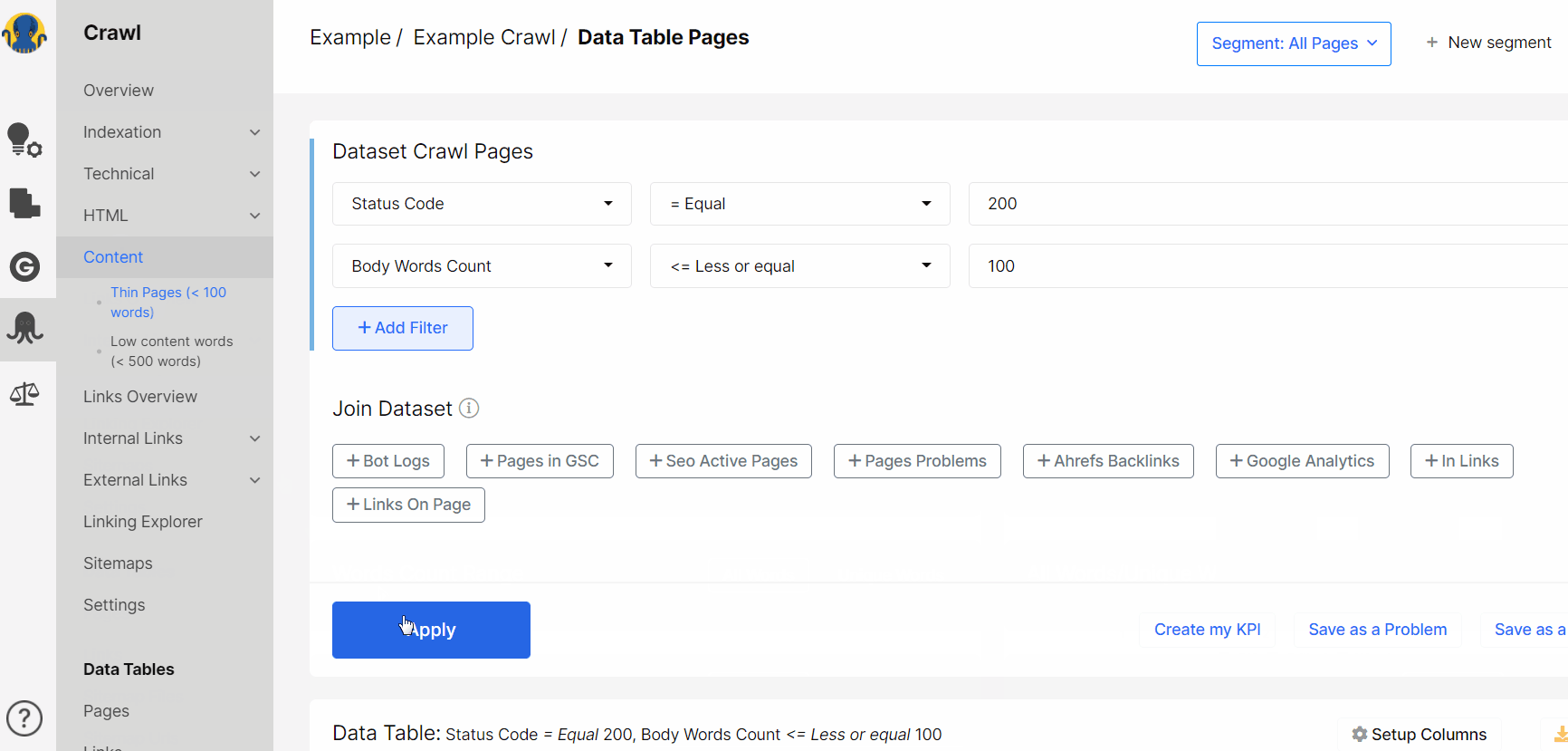
2. You will get the list of concrete URLs with 200 status code and less than 100 words on them.
Chose the Segment “Indexable” on the top of the page to see which indexable pages are affected (learn more on Segmentation. How to analyze website effectively from our short video-guide).
You can download data in Excel (up to 50K pages) or CSV (№of pages not limited) formats.
Now you can send this list to content writers so that they update the thin pages with the relevant information.
Also, you can evaluate the length of the whole content in the Crawl – Content. Click on the group of pages to get the list of concrete URLs.

URLs with low text/HTML ratio
Why
Text/HTML ratio represents the percentage of actual text on the website. There is no ideal Text/HTML ratio. Nevertheless, if there are lots of unnecessary tabs, inline CSS, and comments in a webpage’s code but the actual content is thin, it will be difficult for a bot to crawl your pages. Furthermore, the load time of the page will increase.
How
Go to Crawl – Content with the pie chart with the Text-HTML ratio on your website and the histogram with DFI for these pages.
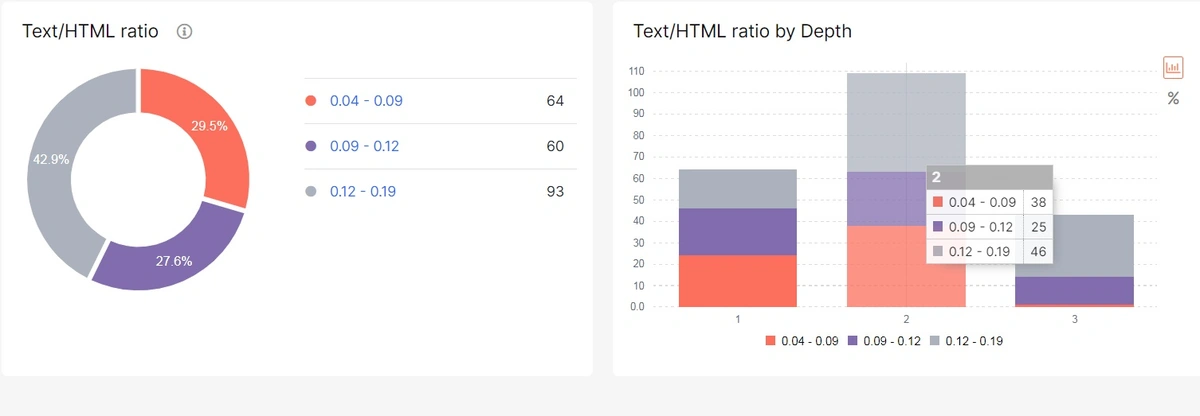
Click on the charts and get to Data Table to the list of URLs with a specific Text-HTML ratio.
You can download data in Excel (up to 50K pages) or CSV (№of pages not limited) formats.
If you have any problems with the crawl,
feel free to send a message to [email protected].
About Ann
Ann is the Content Strategist in JetOctopus. She learned the dynamics of SEO from scratch by understanding the inner workings of logs and crawl reports data. She cross-examines actual SEO cases by studying clients’ websites and loves being an active member of the technical team. Because of her dedication, she has become technically savvy and always bases her definition of quality content on real data and not on speculation. You can find Ann on Twitter and LinkedIn.