
Have you ever thought how many websites there are on the Internet and what is going on with them? I was always wondering if it is possible to see all the domains there are on the Internet instead of analyzing the given small selected number. Here are the results of my research.
- Research and forecast in IT
- Data Mining
- Big Data
- It took around 36 hours to check 252 mln. domains
How many websites do you use every day? Maybe a couple of social networks, some search engines, some favorite media sources, about 5 services for work. You’ll hardly count more than 20 sites.

But have you ever thought how many web-sites there are on the Internet and what is going on with them?
Sometimes I come across some research articles showing selections of different top 1M sites. But I was always wondering if it is possible to see all the domains there are on the Internet instead of analyzing the given small selected number.
I first came up with this idea over a year ago. We were starting developing a crawler for web-sites and had to test it on big sites. Using the crawler’s core I ran through the Runet domains for the first time – 5.5 mln, after that I did the same with all the existing domains – that was 213 mln (autumn, 2017). Since then we’ve dedicated a lot of time and thought to the development, the algorithms became better, so I decided to analyze the Internet once more and to get even more data.
The main purpose of this data collection is to get a realistic selection of working hosts, redirects, servers, and x-powered-by headers.
Techniques of collecting
The app itself is created with Go, we also used our own implementations to work with DNS and HTTP client. Redis as a task queue, MySQL – as a database.
Initially we’ve got only a bare domain of example.com type. The analysis consists of several steps:
- We check availability http://example.com, http://www.example.com, https://example.com, https://www.example.com
- if at least one of them is available:
- we analyze /robots.txt
- we check for /sitemap.xml
Every day there appear and disappear over 100 000 domains. It is clear that it’s practically impossible to get an instantaneous net snapshot, but it should be done as fast as possible.
An additional server cluster made it possible to scan on average 2 000 domains per second. Thus it took around 36 hours to check 252 mln. domains.
As a bit of a tangent
Together with crawling we continue working on “1001 way how to handle abuses”. This is quite a problem when making a more or less big analysis. We’ve taken some pains to improve the algorithm so that it didn’t check the same IP and HTTP several times within a short period of time.
Data
The main figure when analyzing the net is the number of “alive” domains. We call a domain “alive” if it resolves to IP and at least one of these www/non_www http/https gives any response code.
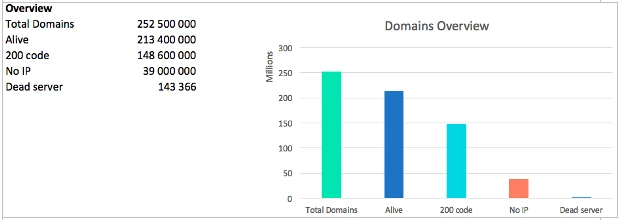
Don’t you forget about the 418 code – teapots: 2227.
The total number of found IP is 3.2 mln. It should be mentioned that some domains give several IPs at a time, others give only one, but each time a different one.
Thus, in general, and on average there are around 16 web-sites on one IP.
The Status Codes picture looks like this:
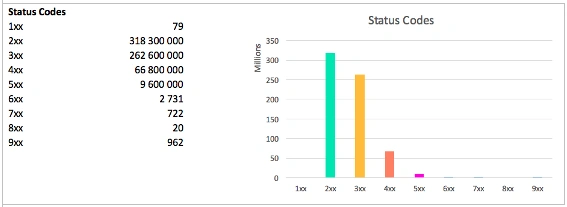
The total number of domains is bigger than that as each host can give 4 different status codes (combinations www/non-www, http/https).
Https
Switching to https has become quite popular recently. SEs keep promoting secure protocols implementation and Google Chrome is about to mark http web-sites as insecure.
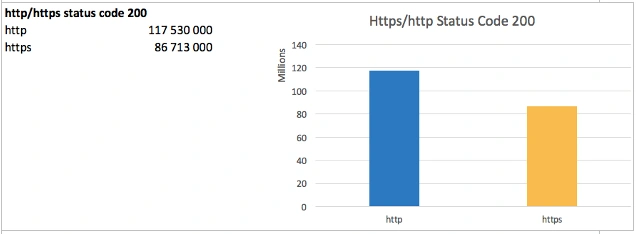
As you can see the proportion of https websites has reached 73% as compared to http ones.
The main problem of such switch is inevitable traffic decrease as SEs regard http/https as technically different sites even if the domain is the same. New projects are usually launched on https from the start.
www or without www?
Subdomain www appeared somewhere together with the Internet, but even now some people can’t stand an address without www.
Moreover, we get the 200 response code from the non www version for 118.6 mln domains, while from the www version — 119.1 mln.
4.3 mln domains don’t have IP tied to the non www version, that means you can’t access the site of example.com type. And 3 mln domains don’t have IP tied to the www version.
What is really important here is the presence of redirects between the versions, as if in both cases we get the 200 response codes a SE regards them as two different sites with duplicated content. So, I’d like to remind you, don’t forget to build correct redirects. There are 32 mln redirects from www->non www, and 38 mln redirects from non www->www.
Looking at these figures I can hardly say which version the winner is — www or non-www.
Redirects
Some SEO experts believe that the best way to promote a web-site is to set up several redirects from the sites of close subject matter.
35.8 mln domains have redirects to other hosts and if we arrange them into groups as intended we can see the leaders:

Traditionally in the top the are domain registration and parking sites.
If you look at the number of less than 10000 incoming redirects you’ll see many familiar web-sites like booking.com.
An in the top of under 1000 one can see casinos and other entertaining sites.
Server header
We’ve come up to the most interesting at last!
186 mln domains give a not empty Header. This makes 87% of all the “alive” domains, quite a positive selection.
If we group them by value we get the following:
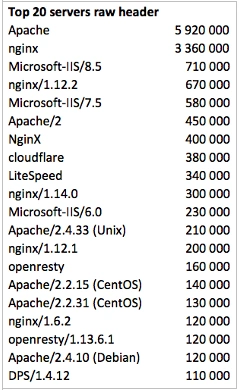
The leaders are 20 servers that in total have 96%:
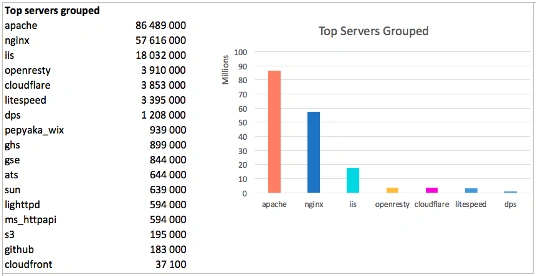
The world leader is Apache, the second place goes to Nginx and the third one goes to IIS. Together these three servers host 87% of the world Internet.
Conservative countries:
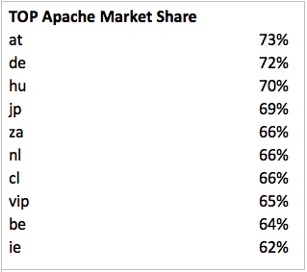
The picture is different with the Runet:
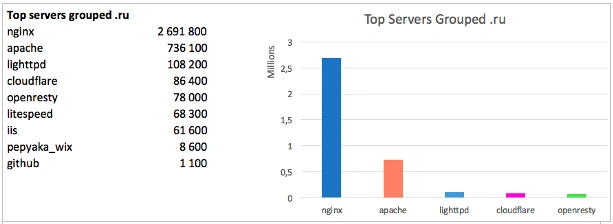
Here we can see that the absolute leader is Nginx and Apache has a share three times less.
Where else Nginx is popular:
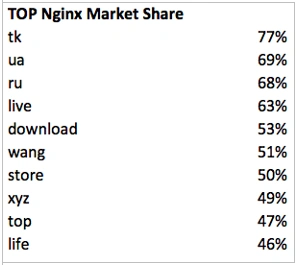
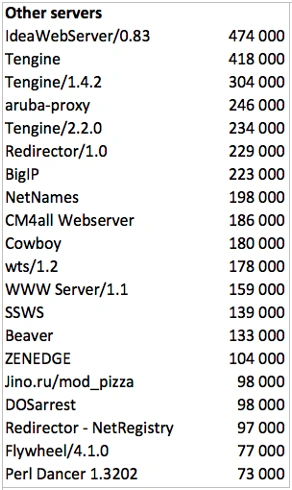
Here is what we get with the rest servers:
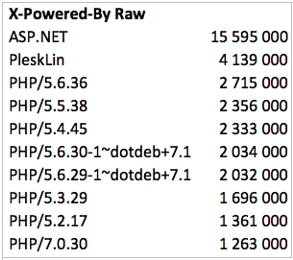
X-Powered-By
Only 57.3 mln hosts have X-Powered-By header, that’s somewhere 27% of all the “alive” domains.
In the rough the leaders are:
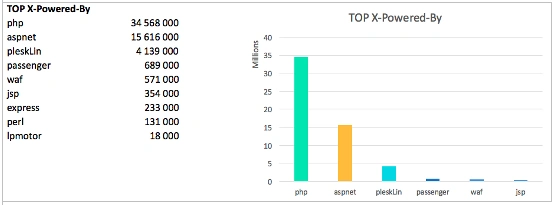
If we process the data and cut away all the fat – we’ll see that php is the one to win:
PHP versions:
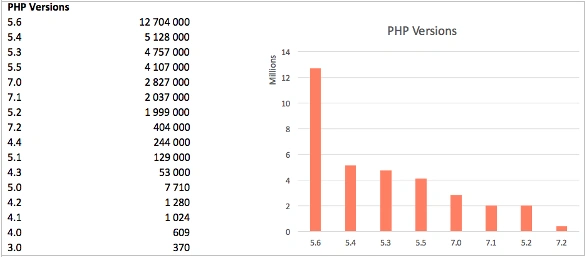
Personally I am somewhat surprised at the popularity of 5.6 and at the same time I’m glad the total number of 7 version is increasing.
There’s one web-site on the Runet that claims that it works on php/1.0, but a shadow of doubt crosses your mind when you hear the version number.
Cookies
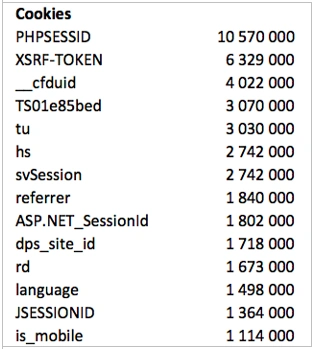
Conclusion
I’ve shown just a small piece of what I found. Searching through these data resembles scavenging in a hope to find some artifacts.
I haven’t covered the questions with blocking search bots and analytics services (ahrefs, majestic and others). There’re quite a number of satellite nets for this selection, doesn’t mater how hard you try to hide the footprints, but you can see consistent patterns when working with thousands of domains.
In the nearest future I’m planning to collect even more data, especially on links, words, advert systems, analytics codes and much more.
I’ll be happy to hear your comments or answer your questions.
Get more useful info TOP 5 fashion shops. Technical epic fails (H&M, Asos, Nordstrom, Gamiss, Uniqlo)










