
Why Partial Technical Analysis Harms Your Website
Have you ever faced SEO drop? So did we. Guided by data of partial crawl, our SEO had deleted relevant content (30 % of the site!) which led to the dramatic traffic drop. The lesson we learned is that partial technical audit is useless and even harmful. Why? Read below to avoid repeating our mistakes.
A hidden thread of partial crawl
Our first business is 5M pages job aggregator Hotwork. We’re looking for new opportunities to increase SEO traffic as fast as possible. Since a comprehensive crawl was time-consuming, we decided to analyze 200K pages. Crawler found a bunch of trash auto-generated content. We thought that the situation on 5M pages was the same and blindly deleted all auto-generated content. That was a crucial mistake!
We expected our traffic and positions would go through the roof but received SEO drop instead. As we found out later, not all auto-generated pages were useless, we blindly deleted relevant pages too.
Only when we went back to square 1, checked each URL manually, and returned profitable pages in the website structure, our traffic increased. This process took us 3 months! We lost a lot of time and effort but we got a priceless lesson. Never replicate the results of the partial crawl on the whole website!
Don’t repeat a story of the liner Titanic, so to speak. The huge ship sank after hitting an iceberg. With partial analysis you see only the top of the iceberg and underestimate the danger.

The earlier you see the real scale of slow load time, wrong status codes, thin-content, duplicates and other crucial technical problems on your website, the more time you have for maneuver.
Let’s look at how partial crawl distorts data on two real cases:
We scanned 1K pages on e-commerce website, though crawler found more than 85K URL-s
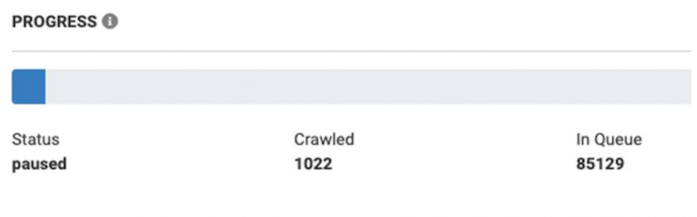
Now let’s see the results of the full technical audit of the same website:
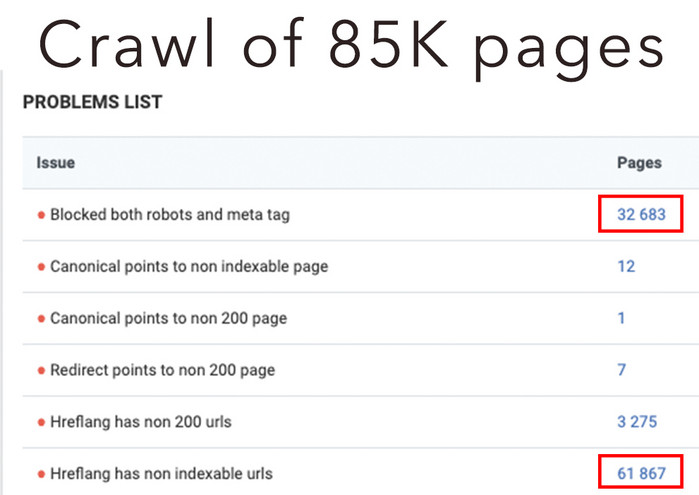
There are more than 32K blocked pages, more than 61K hreflang issues. 52 % of the website is non-indexable and, therefore, this part isn’t ranked in SERP. So, we got an absolutely different picture.
Now let’s check the load time breakdown. Partial crawl revealed a critical issue – 60% of the website loads more than 2 seconds.
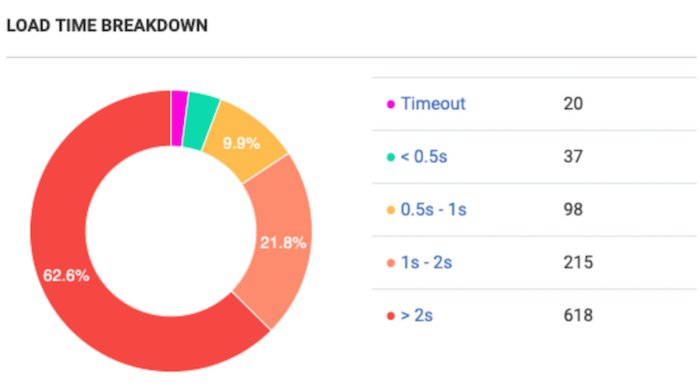
Now compare with the results of the full crawl:
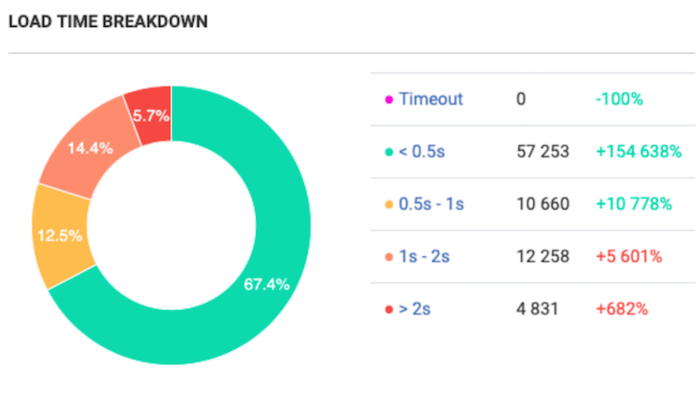
The reality is totally different: 67 % of web pages load quickly enough. So, in this case, load time optimization is not the high-priority task.
Why the results of partial and comprehensive crawls are so different?
Imagine you need to prioritize on-page SEO tasks for this website. If you had the partial crawl data only, what issue would be the high-priority for you? Most likely you would start with load time acceleration, while more than 50 % of your website isn’t indexable. If more than half of a website is blocked, 6% of slow pages – it’s not a big deal, right?
Random Sample of URLs? No way!
If sociologists want to get correct results of the survey, they choose people of different age, gender, and jobs for interviewing. The random sample is the most reliable way to achieve undistorted outcomes. The problem is that bots haven’t learned yet how to pick up URLs in random order.
Technopedia explains web crawler as a tool that analyzes one page at a time through a website until all pages have been processed. Any web crawler scans your URLs one by one, and can’t pick webpages for analysis randomly.
Look at internal linking structure analysis of 300K pages to see how a partial crawl provides misleading insights. The process is as follows: bot starts crawling from the main page and goes deeper and deeper inside the website structure through the links. The more relevant links are on your webpage, the more frequently bot crawls that page.
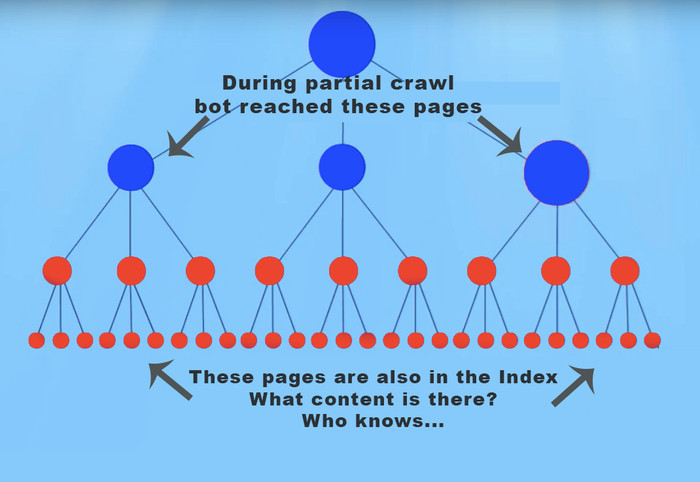
Partial crawl of 100K pages can show well-linked pages but the picture could be totally different on pages with 5,10 DFI. You don’t see the full picture of the internal linking structure and that’s why can’t understand how pages are related.
We’ve recently published a complete guide to internal linking optimization – in order not to lose the point of this article, I will just leave the link here.
Сonsolidation of partial crawl data is time-consuming and risky
The desktop crawlers capacity is limited by memory of the computer they are running on. It’s most likely you’ll crawl only a few thousand URLs per crawl. While this can be normal for small websites with 1-2K pages, it still takes plenty of time gluing together pieces of data into a single picture.
If, for instance, you crawl an e-commerce website with 1M. pages, you need firstly slice it by 200k pages parts, crawl these parts, then put data in Excel (trying to make one big picture and won’t lose any part), and only after you can start searching for meaningful insights. Sounds exhausting and not effective, right?

You also need to take the human factor into consideration. Since one SEO beats his head around a combination of data for a few days, you should give this task to several members of your team. The more people are engaged in the process, the more chances pieces of technical data will be lost. Copy-and-paste approach to analysis requires full attention, but after a while interest to repetitive tasks and quality of work decreases. You can hire a tech geek, who can cope with the processing of partial crawling data, but this is definitely not a scalable approach.
As a result, you waste plenty of time and effort but still get distorted insights. Due to the complexity and scope of the described process, analysis can easily turn to paralysis of your SEO strategy.
Key takeaways
Never replicate the results of partial crawl on the whole website. I’m serious, never. Here is why in a nutshell:
- During partial crawl bot analyzes pages with DFI 2-5, while a bunch of distant pages remains unnoticed. That’s why you can’t access the scope of the technical issue.
- With partial crawl, you get distorted data and that’s why you can’t prioritize your SEO tasks. You can waste your time and efforts trying to fix the insignificant issue while ignoring a huge technical bug on your website. Don’t operate blindly.
- Even if you are motivated enough to crawl the whole website by separate parts, the risk of losing some data is too high. In result, you are wasting your time and effort but still have incomplete results.
Hope I’ve managed to convince you that full technical audit is a Must, have I?
What to read next? Learn how to Work with Rel=canonical Like a Pro
- Category:
- Crawlers
- On-page Tech SEO
About Ann
Ann is the Content Strategist in JetOctopus. She learned the dynamics of SEO from scratch by understanding the inner workings of logs and crawl reports data. She cross-examines actual SEO cases by studying clients’ websites and loves being an active member of the technical team. Because of her dedication, she has become technically savvy and always bases her definition of quality content on real data and not on speculation. You can find Ann on Twitter and LinkedIn.