
There are many situations where search experts talk about conducting partial crawl. For instance, if your website has multiple linguistic versions, you may want the bots to crawl the English version only.
Similarly, you may want the bots to crawl a subdomain only when the URL starts in another subdomain.
However, partial crawling is not always a great idea, especially if you manage a massive website. One of the major reasons for this is that partial crawls will not locate all the errors, thus affecting SEO and leading you to make wrong conclusions.
In this post, we will share why we do not recommend partial crawling and how it can be bad for your SEO.
But first, it’s important to understand what crawling and indexing are all about, how they differ, and how search bots go about it.
Crawling and indexing are the cornerstones of getting web pages to appear in the search results. So, whether we are launching a whole website or adding a page to the site, we need to make sure that the pages are easy to crawl.
This will ensure –
- Easy discovery of the content
- Optimized metadata
- The success of all our SEO efforts
Let’s look at each of these in detail.
What is Crawling?
Crawling is a continual process in which search engines recognize pages that need to be featured in the search results. The search engines send their bots to each URL they find and analyze all the content/code on the page.
What Is Indexing?
Indexing simply refers to store information about all the crawled pages for later retrieval.
But it’s important to remember that not all pages crawled are indexed. There are several situations where URLs aren’t indexed by search engines.
- Exclusion of Robots.txt, a file that tells Google what pages it shouldn’t visit.
- Directives (no index tag or canonical tag) on a page telling search engines not to index a page or index a similar page.
- An error URL like a 404 Not Found HTTP response.
- Search engines consider the page to be of low quality or carrying duplicate or thin content.
- Crawl budget is limited and is not always spent on important commercial pages
How Google Crawls and Indexes a Website?
It is a common misconception that there isn’t much difference between crawling and indexing. However, they are two distinct things.
Search engine crawlers or bots follow an algorithmic process to determine which pages to crawl along with the frequency. As these crawlers move through the page they locate and record links on the pages and add them to their list for crawling later. That’s how the bots discover new content.
While processions each page that’s being crawled, search engines compile a massive index (database of billions of web pages) of all the content it comes across along with their location.
The search algorithm then measures the importance of pages compared to similar pages. The bot renders the code (interprets the HTML, CSS, and JavaScript) on the page and catalogs all the content, links, and metadata.
Here’s a summary of the crawling and indexing process.
- When Google bots come across a page, they will look through the Document Object Model (rendered HTML and Javascript code of the page) to scour the content and assess them. This is only if they are allowed to crawl them.
- The DOM helps bots find links to other pages, thereby allowing them to discover new pages on the web. Each new link is loaded in the queue to be crawled later.
- Since there are billions of pages, search engines spread their crawl over weeks.
- Also, they don’t crawl every web page. Instead, they begin with a few trusted websites. These serve as the basis for assessing how other pages compare.
- They then use the links on the pages to expand their crawl.
- As the crawl proceeds, the bots catalog and organize the content in the index, a database that search engines use to store and retrieve data when a user types a query.
- The index holds –
- Data on the content nature and its topical relevance
- A map of all the pages holding links
- The anchor text of these links
- Additional information on keywords volume, content quality, loading time, page size and links. For instance, are these links promotional? Where are they located?
- Finally, at the ranking stage, search engines interpret the intent of the user query, spot the pages in the index related to the query, and rank/return those pages in order of relevance and importance.
I am sure by now we are clear on how Google and other search engines crawl and index web pages. With that understanding, it’s time we talk about partial crawling and its not-so-good effects on SEO.
The Traditional Method of Partial Crawling with Crawlers
Most large (5 million+ unique pages) and medium (200,000+ unique pages) websites are accustomed to using crawlers that allow partial crawling. One of the reasons why they crawl a few thousand pages of millions is to save the resources. Also, a partial crawl is quicker than a comprehensive one, allowing them to analyze only a part of the web pages.
But would you base your SEO decisions for the whole website on the insights from a partial crawl?
We wouldn’t recommend it! Let’s see why.
Why Is Partial Crawling Bad?
Partial crawling is a wrong approach to crawling as you can never apply its results and analysis to the entire website.
A partial crawl involves crawling a limited number of pages hence offers limited insights for making any SEO decision. In fact, it could lead to a dramatic drop in traffic and is harmful to SEO.
For instance, if you crawl 200K pages of the 5M pages your website has, it may point to issues only in 200K pages.
So, say if there’s auto-generated content in those pages, you will be forced to think that all 5M pages hold such trash content. As a result, you may delete relevant and profitable pages (along with the trash content). Such mistakes can ruin your site’s SEO and it may take months to get back your rankings.
A partial crawl will only point to the top of the iceberg while ignoring the bigger issues. You will never be able to estimate your interlinking structure correctly. This is one of the most powerful ways for big websites to improve their crawl budget and to get all commercial pages visited by search bots. The more internal links there are on a page, the higher crawl ratio will be.
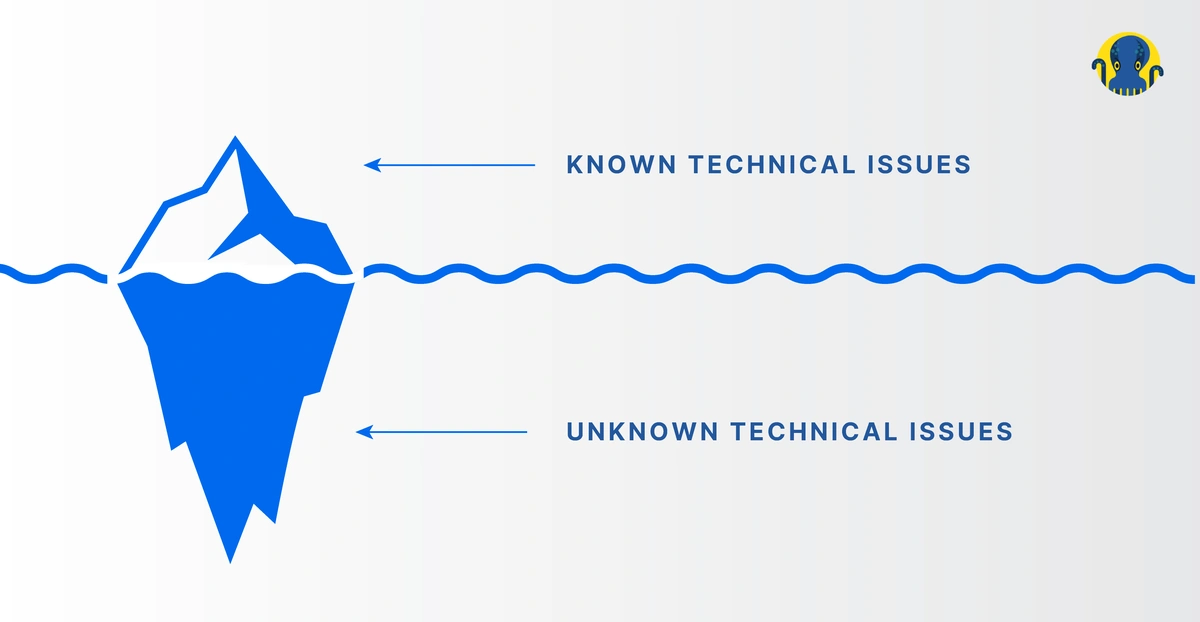
Hence, it’s advisable never to apply the results of a partial crawl to the entire website. You should work with relatively big data extractions to make valid conclusions.
Check out what these SEO experts working on large websites have to say about the partial crawl.
Gennadiy Sivashov, SEO Architect, Scout24 AG
A comprehensive full crawl is great for analytics and to understand exactly which part of the website is not visited by bots/users. It also helps in understanding the reasons, such as weak interlinking, slow loading speed, not enough content on a page, etc.
But to find technical errors, it isn’t necessary to scan the whole website. Usually, the errors after the release are spread for the whole cluster of pages and are fixed somewhere in one place.
In many cases, a full crawl helps understand the scale of a problem to report and say “look, what you’ve done”.
For instance, if something is broken on the category pages, it will be fixed in one component, but the categories used to bring a lot of traffic. From the full crawl, you can show how many pages there are with the error and that this error cost us dramatic decrease in organic traffic. And a loss of money.
Ihor Bankovskyi, Head of SEO, Depositphotos
The more pages being crawled the higher is the possibility of finding a bug. And the more complete picture we have of the interlinking, the better insights you get. If you don’t include any of the site’s segments you will not be able to get the whole picture.
Don’t forget to check our case study: How JetOctopus Helped Depositphotos Index 150 Million+ Pages
Nikita Ezerskiy, Head of SEO, AUTO.RIA
Big websites are supported by different teams, each of them relating to its product. We are talking about different technologies and different problems especially when they cross each other.
One more case is when one of the team changes one technology for another and evident problems arise, especially in those parts of the product that are out of focus. That’s why to find all possible errors I prefer to scan (crawl) all that is available (the whole website) and not the part.
Mikhail Bulanov, Executive Director, Tranio
If you have a classified with 200-300k of active products up to 100k landing pages it means that with a hidden index you have up to 1-2M pages.
These web pages can be quite quickly scanned by JetOctopus where it’s easy to see the whole picture. Plus, it is possible to quickly create all the segments by any regex. It is easy, revealing and quick.
Iryna Rastoropova, Head of SEO, ROZETKA
It’s not that ‘we prefer a full crawl.’ We just don’t have a choice (Screaming Frog cannot be used in our case. Maybe only for the small tasks!).
For big projects, relevant data is a critical question. Owing to frequent launches, there are multiple changes made to the website, a lot of errors happen. Hence, it’s effective to consider it in the context, ‘made a relatively objective data extraction,’ (filtered and received aggregated data). We need to make a conclusion and further analysis based on this.
Why Are the Results of Partial and Comprehensive Crawls So Different?
Bots are very unlike us humans! If humans were to get accurate and undistorted results from a survey, they would randomly choose respondents of various demographics.
However, bots aren’t trained to pick URLs randomly. Crawlers typically analyze one page at a time until all are processed. Hence, a partial crawl will not go deeper into the website structure, offering misleading insights.
Hence, a partial crawl could lead to distorted outcomes.
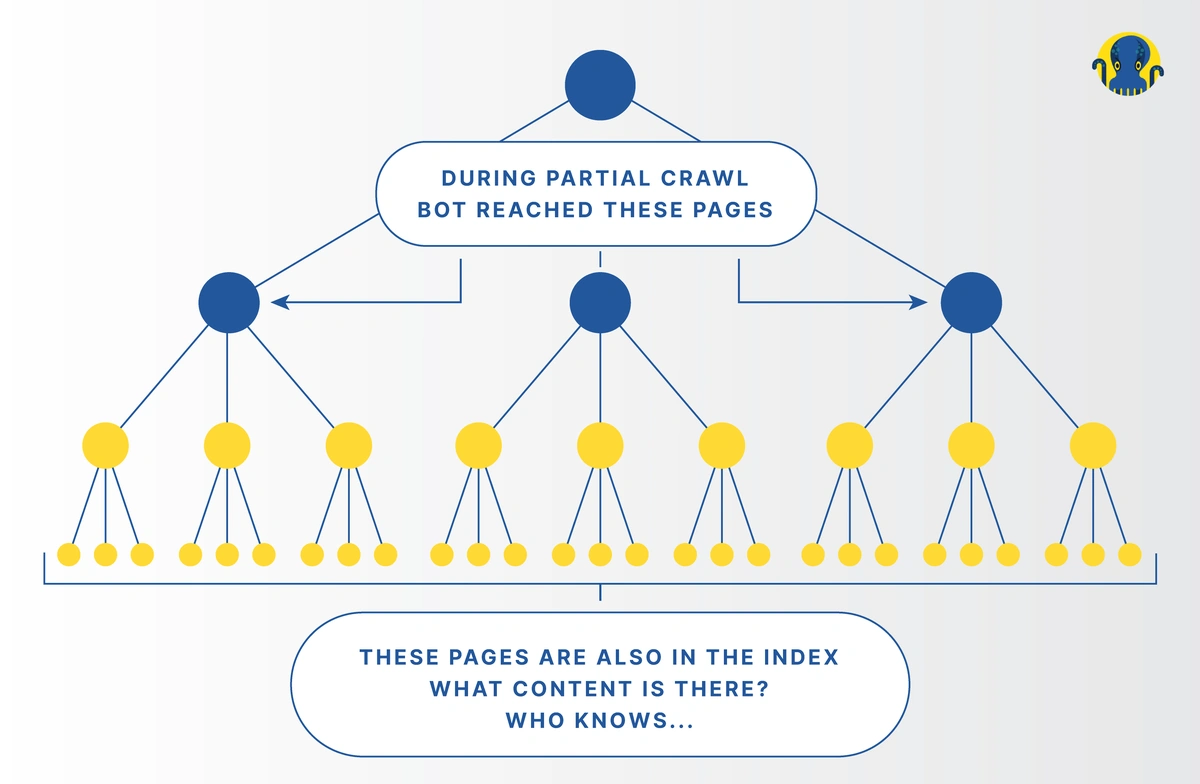
In sharp contrast to this, a comprehensive crawl will go from the main page deeper into the structure through the links. Thus, it will show you the complete picture along with the internal linking structure.
So, a partial crawl of 100K pages will show well-linked pages for that set. But the picture will be different for pages with 5,10 DFI. Also, you will not get a clear understanding of the internal linking structure.
Further, consolidation of partial crawl data is much more time-consuming and risky than a comprehensive crawl. Consolidating partial crawl data for small websites (1-2K) isn’t as tough. However, it can be quite a task for large websites.
Bringing together pieces of data to get the overall picture is challenging and time-consuming.
Imagine crawling an eCommerce website with millions of pages. In partial crawl, you first need to slice them by 200k pages parts, crawl them, add the data to Excel, and then work on deriving insights.

Also, there’s a huge chance of human error. With multiple team members handling the process, the risk of losing critical technical data is high.
Allow us to share a real case to prove how partial crawl distorts insights.
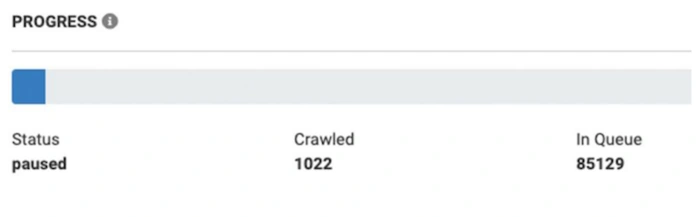
We scanned 1K pages on an eCommerce website. The crawler found more than 85K URLs.
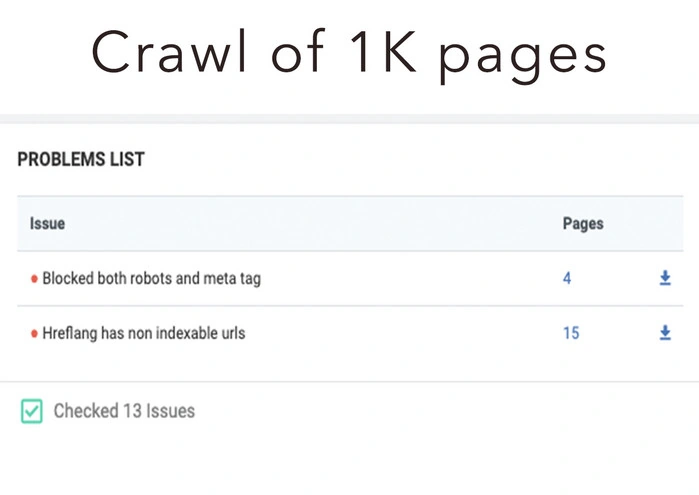
In contrast, here are the results of a full crawl.
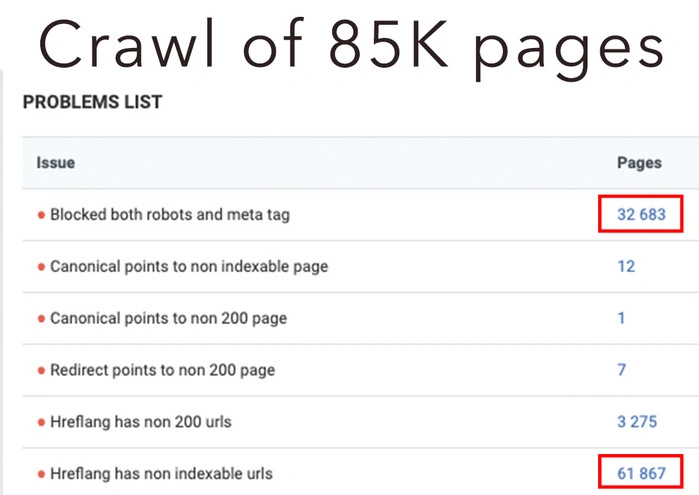
The analysis clearly shows over 32K blocked pages and 60K+ hreflang issues. This is a completely different picture in comparison to the previous report.
When we look at the load time breakdown, partial versus full crawl, here’s what we get.
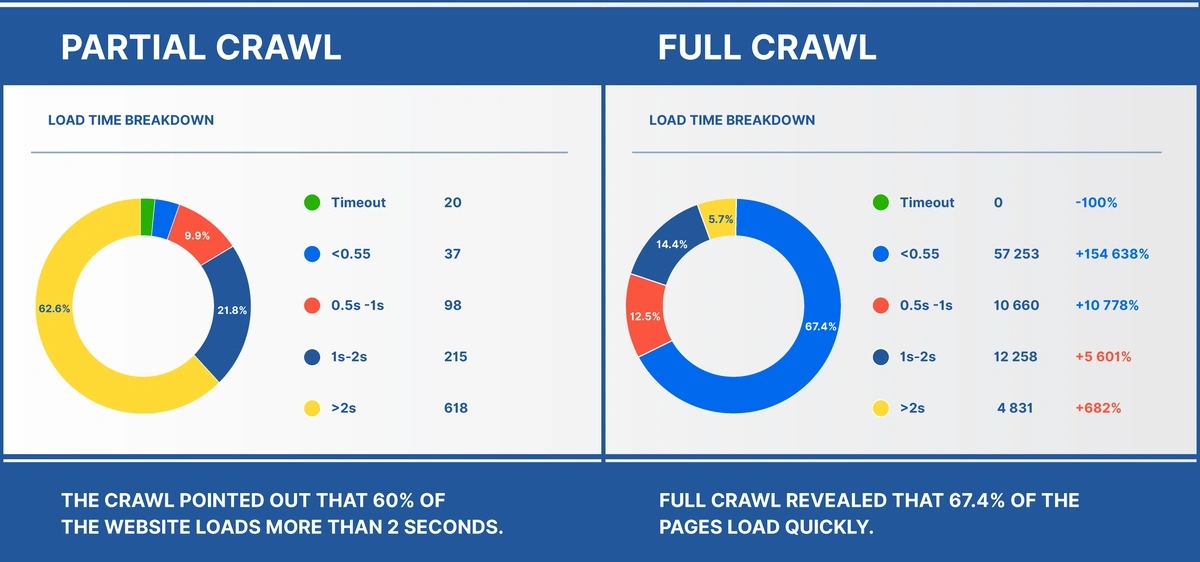
In this case, if a webmaster to go by partial crawl alone, they would prioritize load time optimization while ignoring the most pressing issue – a huge portion of the web pages blocked!
Thus, by relying on partial crawl you are sure to waste your time and efforts.
Not just this, partial crawl fetches distorted insights. Hence, it’s wise to count on an SEO crawler as it is a scalable and quicker approach to deriving accurate insights.
How to Do a Comprehensive Crawl of a Full Website Using JetOctopus?
JetOctopus is the fastest cloud-based SEO crawler that can crawl large websites without negatively affecting your PC. The tool deploys cutting-edge technology to crawl up to 200 pages per second (50K pages in 5 minutes!).
The SEO crawler starts from index pages and crawls all the pages using the internal linking structure. It offers the scale of each problem, allowing technical SEO teams to quickly start fixing them.
Top Features of JetOctopus
- Speed – JetOctopus is ideal for large websites that are looking to get quick and accurate insights from the crawl. As mentioned earlier, the tool exhibits remarkable technical dominance and crawls 200 pages per second.
- Problem-Centric Dashboard – Though JetOctopus offers detailed insights, the dashboard is clean and focuses on the main issues.
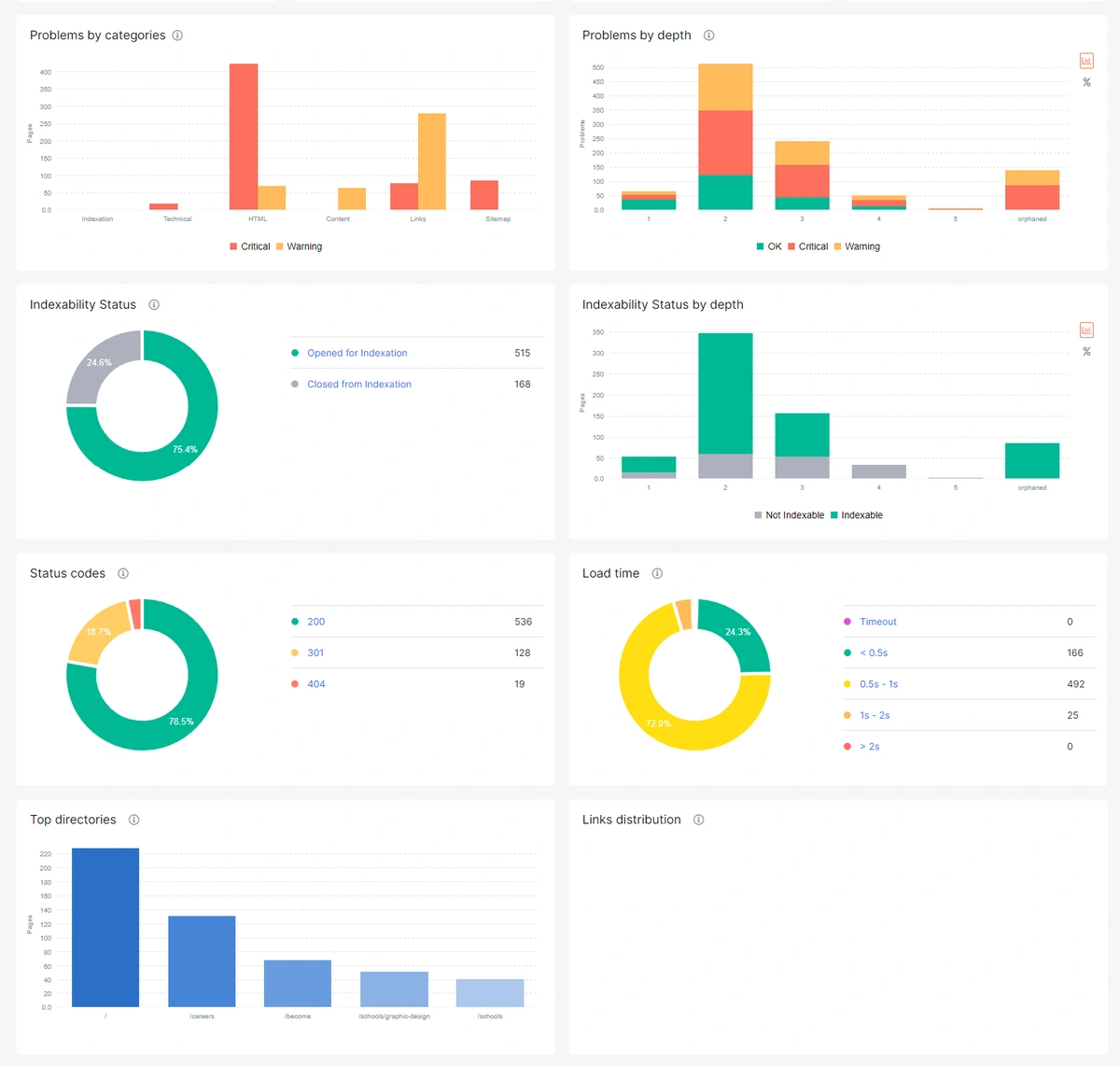
Hence, it’s easy to find the required details and deal with the issues one by one.
- Detailed Content Analysis
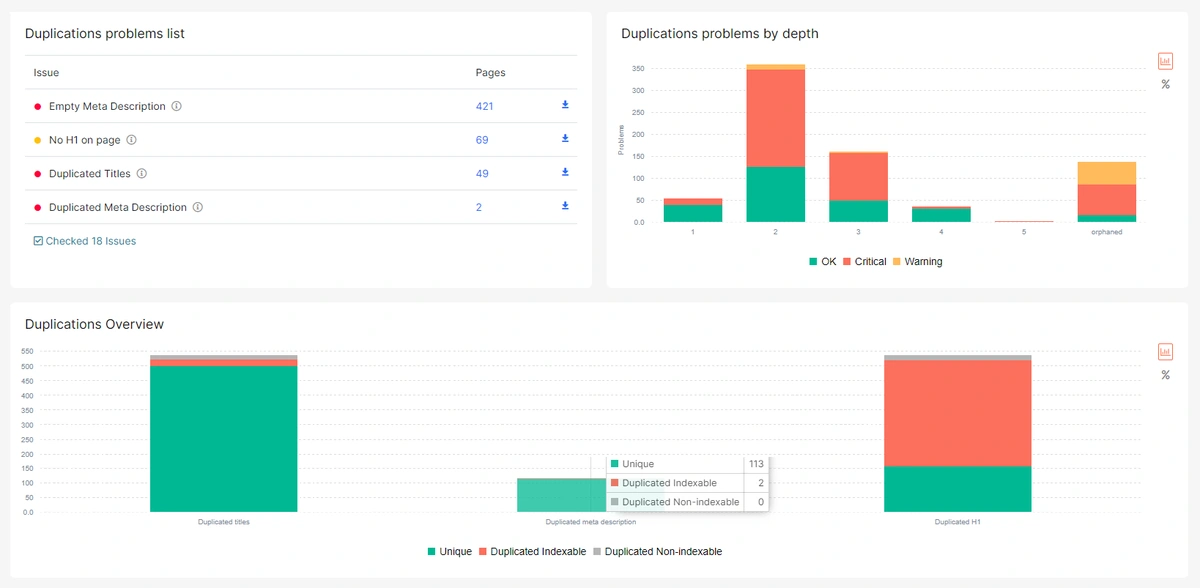
JetOctopus can effectively spot partially duplicate content that’s often missed by desktop crawlers.
- No Project Limits – If you are an agency, project limits often make crawlers useless as you are unable to crawl all your clients entirely. JetOctopus understands this; hence, there aren’t any project limits with this tool.
- Cost-Effective Option – With its cutting-edge technologies and simply genius CTO, JetOctopus makes comprehensive crawling cost-effective. You can crawl the whole website without breaking a bank.
We tested various bases, crawling technologies, link graph processing technologies only to realize that it isn’t impossible to build an SEO crawler at a reasonable cost. All that’s required is a distributed homogeneous system.
Hence, JetOctopus aims at offering large websites and SEOs the power of ‘crawling without limits’ at a reasonable price.
All you need to do is choose a package and leave the rest to us!
Key Takeaways
Relying on partial crawl alone can be risky. The insights derived offer a distorted picture of the technical issue. Since it crawls only a part of the website, you are sure to waste your time and efforts.
The wrong picture will force you to prioritize insignificant issues while ignoring matters that need urgent attention. And not to forget, the loss of data when managing the web pages in separate parts!
In a nutshell, we wouldn’t recommend applying the results of a partial crawl to the whole website.

















