
Non-Canonical URLs Ranking: Case Studies, Stats and Best Practices
Large sites often use rel=canonical to signal the preferred version of duplicate or similar pages and prevent them form ranking in SERPs. SEO specialists state that googlebot very often ignores canonical tags on large e-commerce and enterprise sites, leading to hundreds or thousands of unwanted pages ranking instead of the intended URL.
What are the issues with Non-Canonical pages Ranking
Firstly, this is a result of some default settings in the CMS: many CMSs canonicalize filtered and sorted product feed by default, causing thousands of URLs indexed. So sometimes this happens on websites which don’t get enough SEO attention or expertise. Andrew Birkitt posted about the Shopify limitations where by default your product URLs are placed in a subdirectories (collections) which are canonicalized to the product URLs. Imagine having hundreds or thousands of products hidden behind the layer of non-canonical listings.
Secondly, some SEOs still canonicalize separate page types. Glenn Gabe reported about a large site where tens of thousands of pages were canonicalized to other pages with different content. Google simply ignored the canonicals and indexed those pages anyway. In one audit he found 2,867 URLs indexed and ranked (with impressions/clicks) that were supposed to be canonicalized and non-indexable.
Additionally, Ahrefs studied 374,756 sites using hreflang and as a side finding mentioned that “in many cases, the canonical tag was ignored in favor of the URL specified in hreflang”, illustrating how alternate signals can override a canonical hint.
So while most large sites use canonical tags, a significant number of pages still drain googlebot’s crawl budget, get indexed and ranked causing low-quality UX. And SEOs need to pay attention not only how they canonicalize the pages, but also what other signals they provide to googlbot on canonicalized pages.
Ultimately, Google’s goal is to show the best result. If it judges the non-canonical URL to better satisfy the query, it will index that one, because:
- the content on the non-canonical page satisfies user’s need better
- the content on the canonicalized page is fresher
- the non-canonical page has more internal links
- the canonicalized page loads faster than the canonical one
So why do non-canonical pages get indexed and ranked though?
Well, first, let’s refer to the official guidelines saying: “rel=canonical link in your webpage is a strong hint to search engines about preferred version to index among duplicate pages on the web”.
Secondly this point was explained a bit later by John Muller during the Webmaster Central Hangout:” if the content on canonicalized and canonical pages is different, the bot might think that the canonical tag is a mistake and might ignore it”.
How often do these issues with canonical tags occur?
The exact frequency of non-canonical pages ranking is hard to measure globally, but as an example, 90% of audits by JetOctopus in 2025 detected issues related to wrong usage of canonical tags on big websites in different niches: canonical tag usage to close pages from indexation and combining canonical tags with robots.txt or meta nonidex. Let’s dig deeper into some cases.
Case 1: news aggregator with duplicate pages
The website had 65K pages with get parameters to track the user clicks on page elements. In the logs we found out that there were even more types of (probably legacy) get parameters that googlebot was crawling on daily basis. Those pages drained 13% of monthly googlebot visits:
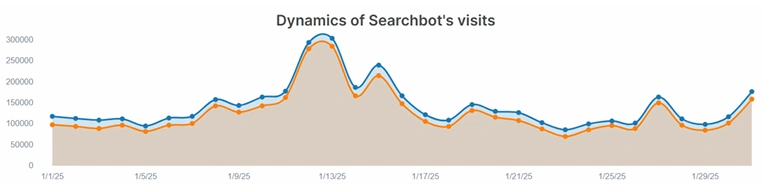
As a result, 71 pages that were indexed and ranked during the observed month, received 1.1M impressions and 228K clicks. Which means even when the content on the pages is 100% same, Google might still choose the non-canonical page to rank.
Case 2: car parts online store and non-canonical PLPs
Website CMS produced a huge volume of paginated canonicalized PLPs and one googlebot decided to crawl them. So these pages drained almost 1M URLs which caused temporary loss in rankings:
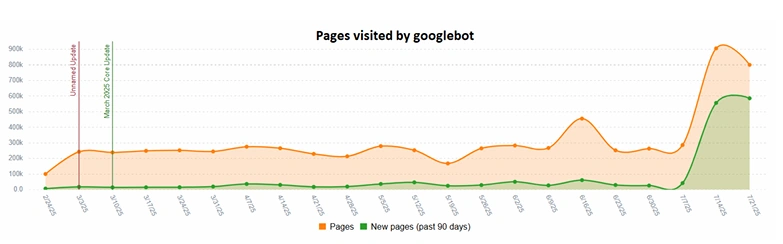
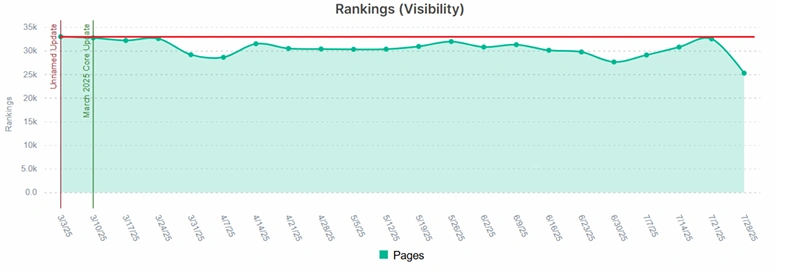
Out of 1M canonicalized pages only 201 ranked during the observed period and acquired 1.5K organic clicks during the period – a huge price in terms of visibility and crawl budget paid for the untimely SEO improvements.
Case 3: car parts classified with parameterized URLs
Website pages have indexable links in filters section and this created almost 200K pages with multiple intersections of random filters. As you can see from the graph below, googlebot constantly crawls new pages every month and visits each URL only one time:
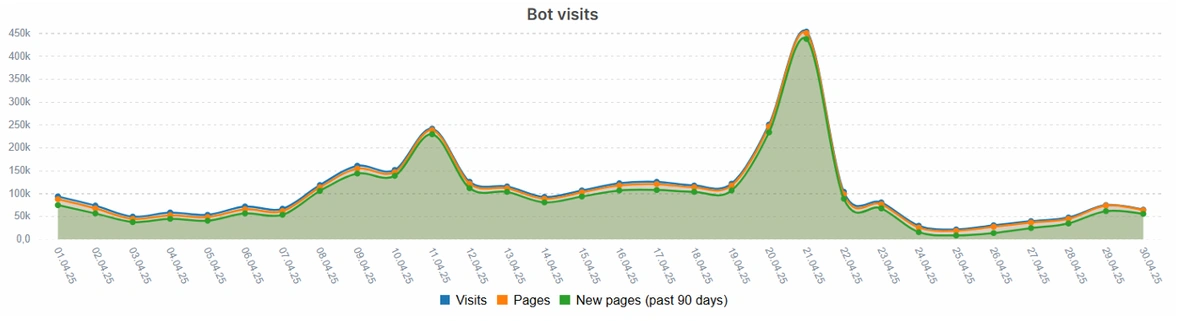
In total, those pages drained 18% of monthly crawl budget, but managed to get only 1.6% of all organic clicks (3.8K pages ranked).
Recommendations: Preventing Non-Canonical Ranking
To minimize Google choosing the unintended page, follow these best practices:
- Use only <meta name=”robots” content=”noindex”> on the pages that shouldn’t be ranked – this is the only 100% guaranteed way to avoid indexing pages that shouldn’t be in SERPs.
- Don’t use <meta name=”robots” content=”noindex”> together with robots.txt directives and/or canonical tags, because this confuses googlebot and pages still get indexed.
- Don’t use canonical tags even for true duplicates – better check if one of the pages could be redirected with 301 or 308 response.
- Don’t link to non-indexable or canonicalized pages in hreflang tags.
- Remove internal links to canonicalized pages or pages that you don’t want to rank in SERPs. Replace them with buttons or elements substituted by JS.
- Crawl your website at least bi-weekly to see any unintended changes in website structure or volume of pages.
- Monitor your server logs because googlebot remembers about all the URLs that have been on your website and might try to doublecheck them again.
- Create the alerts for logs and crawls to get instant notifications and not miss any change that could bring critical consequences.
Conclusion
In conclusion, non-canonical URLs damaging your site has become a common problem for large and complex sites. Canonical tags alone are just hints to googlebot which it might not follow and ignore. As the result: wasted crawl budget, visibility losses, polluted website index, wrong pages shown in SERPs and low-quality on-site user behaviour. To stay in control, SEOs must strongly understand which pages should be indexed, be flexible and creative in configuring internal linking and website structure and watch your website’s tech health.
About Stanislav Dashevskyi
Stan is a long-time JetOctopus user and currently is the Head of Customer Success (SEO) of JetOctopus. SEO analyst since 2013, SEO tutor and Tech SEO enthusiast. You can find Stan on LinkedIn.