JetOctopus new product update is out! You can now compare two different crawl reports and see crawl evolutions! With our unique module, you will be able not only to watch SEO dynamics in overall but also to compare changes in segments of your website. This approach helps to identify the strengths and the weaknesses of each segment on your website and replicate successful experiments on the whole website. Let’s focus on real benefits you can take from our new module to maximize your ROI.
What’s inside:
- Boundless Comparison
- Comparison of Segments
- Visualization of Comparison Data
- Never Seen Before Speed
- How to filter Data For Your Specific Needs
1. Boundless Comparison
Some web crawlers provide comparison features but they only offer the comparison of the last report with the second-to-last report. JetOctopus provides the boundless comparison of any crawl report with any other existing crawl report. This feature allows one to detect issues evolutions and clearly see how your solutions work. It’s a good retrospective opportunity.
Imagine that the engine in your car broke and you need to replace broken details. You’d changed one detail, but the engine didn’t operate at full capacity. You replaced that detail with another one and compared results. The same way you can slice and dice the SEO process and compare which solution works best for your website.
Your website and Google algorithms are constantly developing and that’s why data in crawl reports could vary widely even in short terms. Some problems are fixed while new problems appear. To see the dynamics of issues, you should know how many problems your website contains now (current crawl), how many problems were found previously (compared crawl), how many new problems were detected (new pages), how many problems were fixed (dropped out pages).
Сoming back to the example of a broken engine in your car, to estimate how much you’ve spent for the repair and how you can reduce the cost of repair in the future, you should know how many details are broken (current state), how many details should be replaced now (new problems), and how many details were replaced in the past (dropped out pages).
For example, you crawled your website last week and found duplicate content.
Crawl report 1
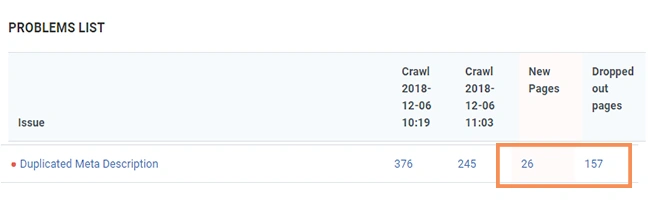
There are multiple recommendations to address this problem, but you should find the most effective solution in your particular case. You decided to implement 301 redirects and after recrawl the picture is: 157 duplicate meta descriptions were fixed (dropped out pages) and only 26 new were found (new pages).
Crawl report 2
Good results, but you need to fix the other 245 issues. You decided to block Googlebot access to duplicate content with a robots.txt file. But after recrawl you got negative results: only 13 duplicate meta descriptions were fixed (dropped out pages), but 334 new issues were detected (new pages)!
Crawl report 3
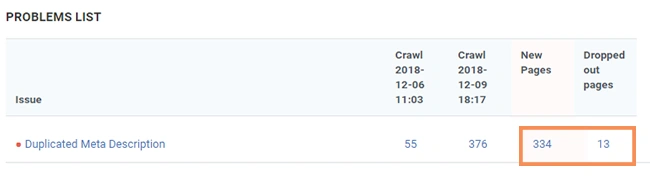
You found out that if Google can’t crawl webpages with duplicate content (in this case because of robot.txt), it can’t automatically detect that these URLs point to the same content and will therefore effectively have to treat them as separate, unique pages. So, the above-mentioned solution is ineffective.
Webmaster advised using the rel=”canonical” link element to solve the duplicate meta descriptions issue. You deleted robot.txt files, implement rel=”canonical” links + 301 redirects and achieved the best results: there are only 3 duplicate meta descriptions and 365 solved issues.
Crawl report 4
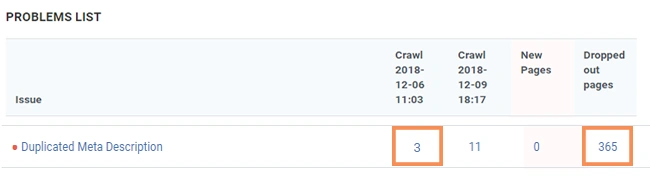
This case shows that flexibility in analysis helps to extract actionable conclusions from your data. The module of crawls comparison allows revealing optimizations that generate the most value.
2. Comparison of Segments
Grouping webpages by different metrics really eases your workflow. Segment is a tool that slices your website to as many categories as you need so that you can watch crawl data within your particular segment without recrawl. By default there are two built-in segments: All pages and Indexable pages, but you can create an unlimited number of segments for holistic comparison.
Imagine your e-commerce website is developing and you are working hard on increasing sales of a new brand. You implemented thousand of new product webpages but for some reason Googlebot takes only a few fresh URLs in search engine index. One of the simplest ways to find the reason for this issue is to compare the new segment with other recently crawled similar segments which are indexed much better.
Then check technical parameters which could influence indexability of new webpages. In this example the main reason was in slow load time: number of webpages that load longer than 2 seconds increased by 422 % in comparison with the similar segment.
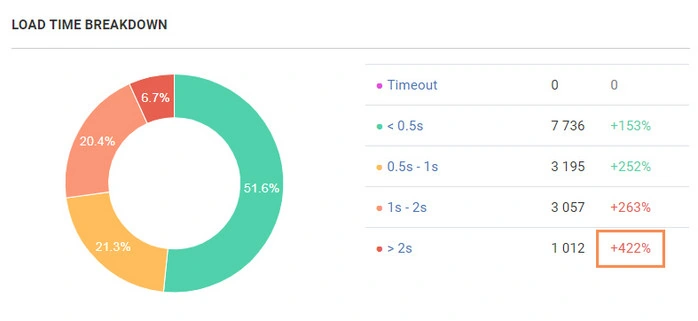
Googlebot just wasted a crawl budget waiting for the response from slow pages. Now you have the right data to take action. You can also click on any parts of the graph to identify the concerned URLs and export them in Excel or CSV.
3. Visualization of Comparison Data
JetOctopus makes your dashboard as empty as possible leaving you with vivid graphs so that you could visualize the main problems in the full scale from the very first second of crawl report comparison. Pie charts and histograms are perfect for communicating broader trends, as they can open tendencies that are otherwise obscured within the raw lists of URLs. Red numbers reflect negative tendencies while green numbers display positive changes.
Bright columns in histograms show current crawl data, blackened columns display compared data. The color of the columns indicates how the problem is critical for your SEO. Data is available in relative and absolute values.
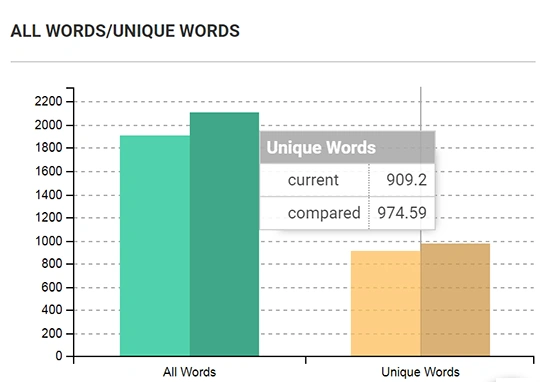
Visualization allows you to drill down into the comparison. All graphs are interactive: once you click on the chart, you get to the Data Table menu with the list of related URLs.
4. Never-Seen-Before Speed
JetOctopus is a cloud-based crawler with remarkable technical predominance. Cutting-edge technologies used in JetOctopus let us crawl 200 webpages per second and 10,000 webpages in less than a minute! With such a speed you can recrawl your website and compare results several times a day (for instance, after big products update or website migration). If your website contains 1M URLs, it takes from 2 hours to 2 days (depending on your website capacity) to crawl all webpages with JetOctopus. You won’t wait till Googlebot finds bugs on your website, you will be able to detect and fix all bugs before Googlebot does it.
5. How to filter Data For Your Specific Needs
Once you click on interactive charts, you get to the Data table with the list of related webpages. Five prior filters are available here: current crawl – data from the current crawl; compared crawl – data from the crawl you compare; exist in both crawls – identic data in both crawls; new pages – the pages which appeared in this list after current crawl and which were not there in the compared crawl; dropped out pages – the pages which disappeared from this list in compared crawl after implementing changes.
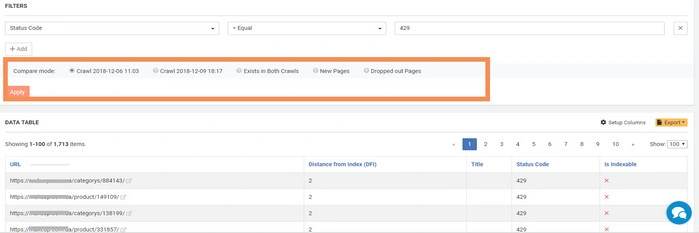
Moreover, JetOctopus provides additional 154 (!) filters for in-depth study.
When you finish filtering, you are able to export the results to CSV or Excel. These reports allow revealing the most impactful changes you can make to drive the most organic traffic and increase ROI.
To sum up:
We were working hard to release a useful product update and we hope you will appreciate it. Crawls comparison feature allows you to:
– compare any historical crawl with the current one;
– compare Segments from different crawls to watch the impact of product updates;
– compare different Segments within one crawl so to see the difference between the more effective Segment and the less effective one and implement obvious changes;
– compare different Segments from different crawls;
– speed of crawl is still very exciting! Make several crawls per day, compare after product updates, and know for sure all your successful SEO experiments.
Enjoy your adventure!
Get more useful info Product Update: Linking Explorer – a database on interlinking for each page
















