
Robots.txt: 8 Common Mistakes and How to Avoid Them
Yes, Robots.txt can be ignored by bots and yes, it’s not secure: everyone could see the content of this file. Nevertheless, well-considered robots.txt helps to deliver your content to bots and omit low-priority pages in SERP. At first glance, giving directories is an easy task but any kind of management requires your attention. Let’s go through common Robots.txt mistakes and ways to avoid them
Essentials
We don’t want to sound like a broken record repeating the definitions and the main rules of robots.txt. There are a variety of useful guidelines that describe robots.txt basics in details. We’ve gathered the most relevant sources in the clickable list for your convenience:
- Google: What is a robots.txt file?
- Google: Create a robots.txt file
- Google: Test your robots.txt
- Google: Robots.txt Specifications
- Wikipedia: Robots Exclusion Protocol
- Moz: Robots.txt Basis
- Search Engine Journal: Best Practices for Setting Up Robots.txt
Now let’s cut to the chase and reveal the most common robots.txt mistakes & ways to avoid them.
Mistakes in Robots.txt To Avoid
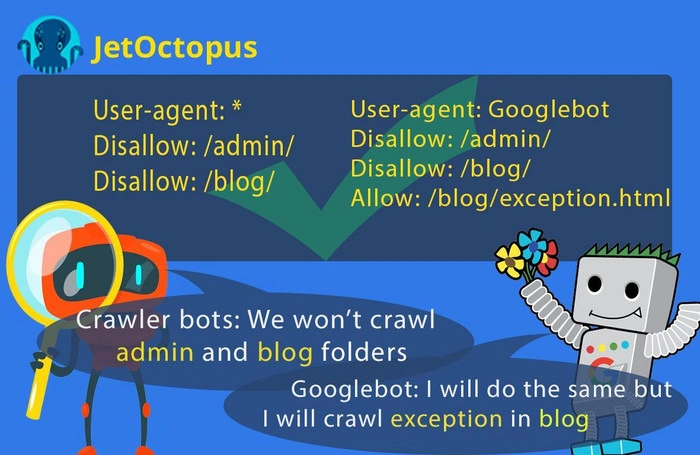
1. Ignoring disallow directives for specific user-agent block
Suppose you have two categories that should be blocked for all crawlers and also one URL that should be available only for Googlebot:

This file asks Googlebot to scan the whole website. Remember that if you name the specific bot in robots. txt, it will only obey the directives addressed to it. To specify exceptions for Googlebot, you should repeat disallow directives for each user-agent block, like this:
2. One robots.txt file for different subdomains
Remember that subdomain is generally treated as a separate website and thus follows only its own robots.txt directives. Suppose your website has a few child domains that serve different purposes. You can try to take the easy way out and сreate one robots.txt file with the aim to provide your subdomains from it, for instance:

Well, it isn’t that easy. You cannot specify a subdomain (or a domain) in a robots.txt file with a wave of a magic wand. Each subdomain should have the separate robots.txt file. For instance, this file opens access to everything on the subdomain “admin”:
Robots.txt works only if it is present in the root. You need to upload a separate robots.txt for each subdomain website, where it can be accessed by a search bot.
3. Listing of secure directories
Since Robots.txt is easily available for users and harmful bots, don’t add private data as illustrated by the following examples:

We do not live in an ideal world, where all competitors respect each other. When you are trying to disallow some private data in robots. txt, you give fast access to your information for bad bots. It’s like sticking a note with a polite request on your backpack:
“Dear thieves! I have 1000 dollars in the left pocket. Please, don’t touch it! Thank you so much!”
The only way to keep a directory hidden is to put it behind a password.
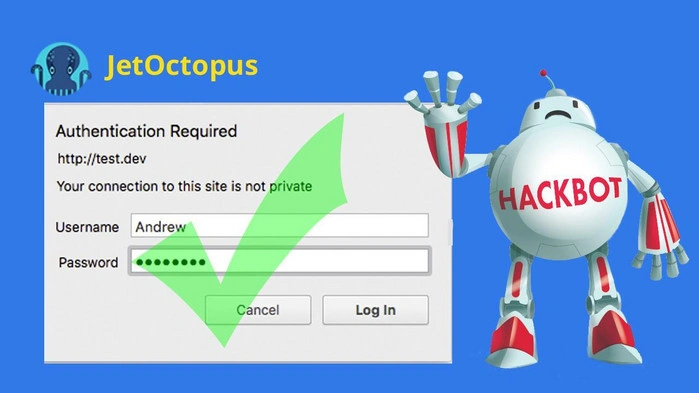
Remember: secure data = password-protected data. That is the only reliable way to protect such sensitive data like customer credit card details or credentials.
Also, note that Google can index pages blocked in robots.txt if Googlebot finds internal links pointing to these pages. In a scenario like this, Google will likely use a title from some of the internal links pointing to the URL, but the URL will rarely be displayed in SERP because Google has very little information about it.
4. Blocking relevant pages
Very often webmasters accidentally close profitable pages by the following way: suppose you need to block all data in the following folder – https://yourbrand.com/key/ So, you will add the following lines in the robots. txt:
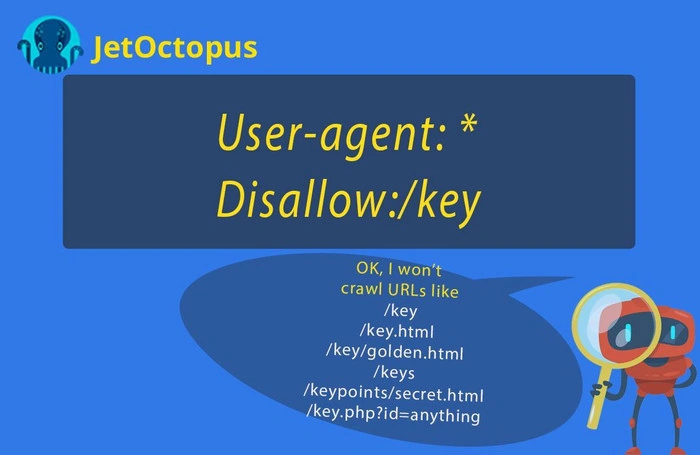
Yes, now you’ve protected the credentials of your clients, but you also blocked the relevant pages like: https://yourbrand.com/keyrings-keychains/?ie=UTF8&node=29
This blunder can harm your SEO efforts. With the exception of wildcards, the path is used to match the beginning of a URL (and any valid URLs that start with the same path).

Two slashes /…/ separate a distinct category of URLs, in our case we ask not to crawl the whole content in /key/ category but if we add just one slash /key after Disallow, we block all links which begins with the key combination of symbols. The dollar specification designates the end of the URL, it tells search bot – “the path ends here.”
5. Forgetting to add directives for specific bots where it’s needed
Google’s main crawler is called Googlebot. In addition, there are 12 more specific spiders each of which has its own name as User-agent and crawls some part of your website (for instance, Googlebot-News scans applicable content for inclusion on Google News, Googlebot-Image searches for photos and images, etc.)
Some of the content you publish may not be applicable for inclusion on SERP. For example, you want all your pages to appear in Google Search, but you don’t want photos in your personal directory to be crawled. In such a case, use robots.txt to disallow the user-agent Googlebot-image from crawling the files in the directory (while allowing Googlebot to scan all files):

One more example – suppose you want ads on all your URLs, but you don’t want those pages to appear in SERP. So, you’d prevent Googlebot from crawling, but allow Mediapartners-Google bot:

6. Adding the relative path to sitemap
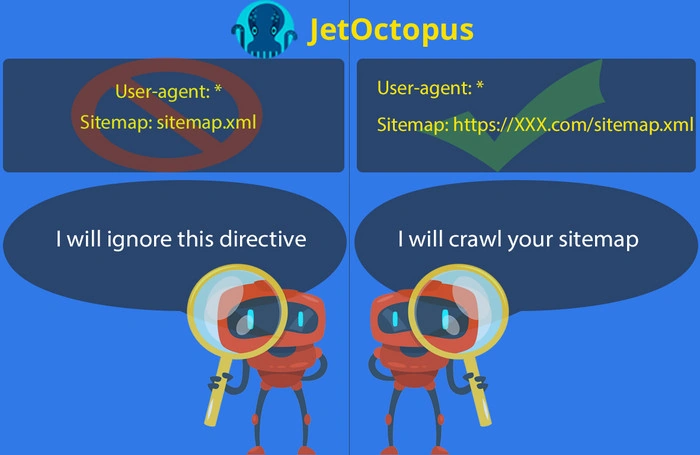
Sitemap assists crawlers in faster indexation, and that’s why it should be submitted on your website. Also, it’s a good idea to leave a clue to search bot in robots.txt about where your sitemap is placed.
Note that bots cannot reach sitemap files using a relative path, URL must be absolute.
7. Ignoring Slash in a Disallow field

Search bots won’t respect your robots.txt rules if you miss a slash in the correlated section.
8. Forgetting about case sensitivity
The path value in robots.txt is used as a basis to determine whether or not a rule applies to a specific URL on a site. Directives in the robots.txt file are case-sensitive. Google says you can use only the first few characters instead of the full name in robots.txt directories. For example, instead of listing all upper and lower-case permutations of /MyBlogException, you could add the permutations of /MyE but only if no other, crawlable URLs exist with those first characters.
Wrapping Up
A little text file with directives for search bots in the root folder could greatly affect crawlability of your URLs and even the entire website. Robots.txt is not as easy as it may seem: one superfluous slash or missed wildcard could block your profitable pages or vice versa open access to duplicate or private content. JetOctopus crawler reveals each webpage that is blocked by robots.txt, so that you can easily check whether Disallow/Allow directives are correct.
We have a client-oriented philosophy, so if you have any questions about technical SEO in general and robots. txt file in particular, feel free to drop us a line [email protected]
Get more useful info Simple Lifehack: How to Create a Site That Will Never Go Down
- Category:
- How to guides
- On-page Tech SEO
About Ann
Ann is the Content Strategist in JetOctopus. She learned the dynamics of SEO from scratch by understanding the inner workings of logs and crawl reports data. She cross-examines actual SEO cases by studying clients’ websites and loves being an active member of the technical team. Because of her dedication, she has become technically savvy and always bases her definition of quality content on real data and not on speculation. You can find Ann on Twitter and LinkedIn.