
When search bot crawls your website and finds similar data on multiple URLs, it doesn’t know how to treat your content. In most cases, bot trusts the clues you give it (unless you trying to manipulate search results). So, the game plan is to specify which pages are original and which are appreciably similar. Let’s find the best way to do it.
TLTR
Canonicalization is a way to tell Google which pages are preferable for indexation and ranking, and which are not. Unless you want to confuse bots, respect these Don’ts:
- Don’t mark a few URLs as canonical for the same webpage.
- Don’t use robots.txt for canonicalization.
- Don’t block duplicates with noindex tag or HTTP header.
- Don’t link to the duplicated URL within your website.
- Don’t insert duplicates in the URL removal tool in GSC.
- Don’t canonize HTTP URLs.
Depending on your main aim, choose one of the 4 proven ways to canonize your URL:
- Rel=canonical to canonize HTML pages.
- Rel=canonical HTTP header to canonize non-HTML files.
- 301 redirect to move your content permanently to the new location.
- XML Sitemap as an additional way to show Google your preferable content (all URLs in the sitemap will be treated as canonical content)
Are you sure you don’t have duplicates?
A canonical URL is a page that Google perceives as the most relevant from a few duplicate URLs on a website. Maybe you think, ‘I don’t copy any URL, so there is nothing to worry about.’ In fact, duplicates can be automatically generated.
For instance, search crawlers might be able to reach your landing page in different ways:
HTTP and HTTPS protocols
- http://www.yourwebsite.com
- https://www.yourwebsite.com
WWW and non-WWW
- http://example.com
- http://www.example.com/
What path to your website is preferable? Choose the best way and don’t forget to tell Google about your choice.
Let’s move on. E-commerce sites provide different paths to similar content. URL parameters for sizes, colors, brands, etc. generate thousands of duplicated pages. Here is the in-depth guide on e-commerce duplicate content
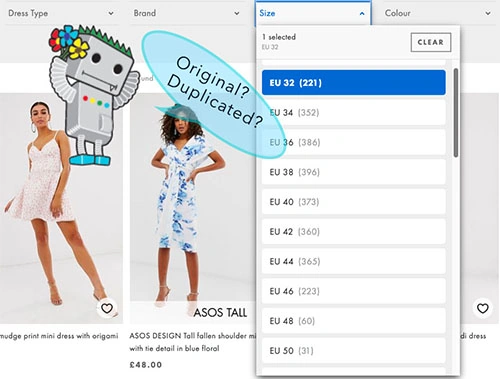
Of course, you don’t want to create duplicates deliberately but parameters can cause this issue automatically. Large-scale duplication may dilute your ranking ability. Nevertheless, even if your content does rank, Googlebot may pick the wrong page as the high-priority. Using canonicalization helps you control duplicate content.
You can canonize the URL using different approaches. We will talk about pros, cons, and specificity of each method below but firstly, let’s go through the general rules you need to respect whichever method you choose.
Canonicalization: General DON’T
Don’t mark a few URLs as canonical for the same webpage. Suppose you specify page A as a canonical version of your content with rel=canonical tag in code and also canonize page B in the sitemap. Oops, you’ve just confused the Googlebot and it hates to be confused. Canonize your content attentively and always choose only one URL as the original.
Don’t use rel=canonical link tag/ HTTP header on category filters pages. With a bunch of possible combinations of filters on e-commerce website (colour, sizes, brand etc.) for each item on the site, search bot could waste a ton of your crawl budget crawling in and out of navigational filters. Whilst the rel=canonical element will help you avoid duplicate content issues, this approach won’t save you any crawl budget. Furthermore, canonical tags can often be ignored by search engine bots so you should use this in conjunction with another approach, to direct search engines toward the preferred version of each page.
Don’t use robots.txt directives for canonicalization. Robots.txt is a roadmap to Google, it shows which URLs should be crawled, and which should be ignored. Nevertheless, robots.txt shouldn’t be used for canonicalization. Googler John Muller confirms that:
Don’t block duplicates with noindex meta tag or HTTP header. This directive prevents URL from appearing in SERP, and not the way of canonization.
Don’t link to the duplicated URL within your website. If you specify some version of the content as canonical, you consider it original, relevant, and the most profitable version. It’s strange for Google when you are building an internal linking structure on duplicated URLs. That confuses Google and, as we found out above, Google hates to be confused.
Don’t insert duplicates in the URL removal tool in Google Search Console. This method temporarily hides ALL duplicated and canonical versions of your URL from SERP. By blocking a page on your website, you can stop Google from indexing and ranking that URL. In other words, users won’t be able to see or navigate to canonical as well as duplicated version of the URL.
Don’t use HTTP URL as canonical when you have the version with HTTPs protocol. Google prefers HTTPS over HTTP URLs as canonical
4 proven ways to canonicalize your URL
1. Rel=canonical tag
Setting this tag is similar in concept to a 301 redirect, only without actually redirecting. With this tag you can canonize as many URLs as you want. Implementation is simple: insert link tag with the attribute rel=canonical from the non-canonical (duplicated) URL to the canonical one in the HTML code of your webpage.
Note that this tag only works for HTML URLs. Here is how to work with rel=canonical tag like a pro
2. Rel=canonical HTTP header
You should add the rel=”canonical” HTTP headers (rather than Rel=canonical tag) to indicate the canonical URL for non-HTML documents such as PDF files. For example, you may offer information about prices and HTML page and also via downloadable file in PDF:
- http://www.example.com/price.html
- http://www.example.com/price.pdf
Since both files serving up the same information, a server-side canonical tag is a good solution.
3. 301 redirect
A redirect is a way to send both visitors and Google to a different page from the one they originally see. You should use 301 redirects if you are moving your website to a new location, changing your URLs to a new structure or if you have expired content on your website such as old products or news items.
4. XML Sitemap
URLs in your XML sitemaps are often used to define your canonical URLs. Googler John Muller confirmed that during English Google Webmaster hangout:
…we use sitemaps URLs as a part of trying to understand which URL should be the canonical for a piece of content.
Pay attention that Googlebot still determines the associated duplicate for any canonicals that you declare in the sitemap files. Also, note that sitemaps are less strong signals to Google than the rel=canonical method.
Keep learning
I gathered the list of relevant guides and cases to dive deeper into canonization methods:
Google: How to tell Google about your duplicate content
JetOctopus: How to work with Rel=canonical Like a Pro
Nick LeRoy. SEO case: Canonical giftings content across web properties
Kristina Azrenko: The extensive guide on e-commerce duplicate content















