
Most SEO audits stop at what crawlers and analytics platforms report. Log files go further: they record what search engines actually did on your server, with no sampling, no estimation and no third-party interpretation.
This checklist is built for SEOs who need that level of precision: practitioners managing large or complex sites where crawl budget is finite, indexation gaps have real revenue consequences and “I think there might be an issue” isn’t good enough to move an engineering team.
Across 18 checkpoints, you’ll learn how to read Googlebot’s behavior as a diagnostic signal: identify crawl waste, uncover orphaned and unvisited pages, spot errors that affect rankings and build a data-driven case for the fixes that matter most.
If you already know log file analysis is valuable but haven’t made it a consistent part of your workflow, this is the guide that changes that.

What`s inside:
- Define crawl budget
- Identify crawl budget waste
- Identify orphaned pages
- Identify the not-visited pages
- Analyze bot behavior by DFI
- Analyze bot behavior – inlinks
- Check content size
- Find title issues
- Identify the most visited pages
- Identify the least visited pages
- Find non-index pages
- Identify hreflang issues
- Spot HTTP status codes
- Load time
- Mobile indexing
- JS rendering failures
- User experience
- SEO & AI efficiency
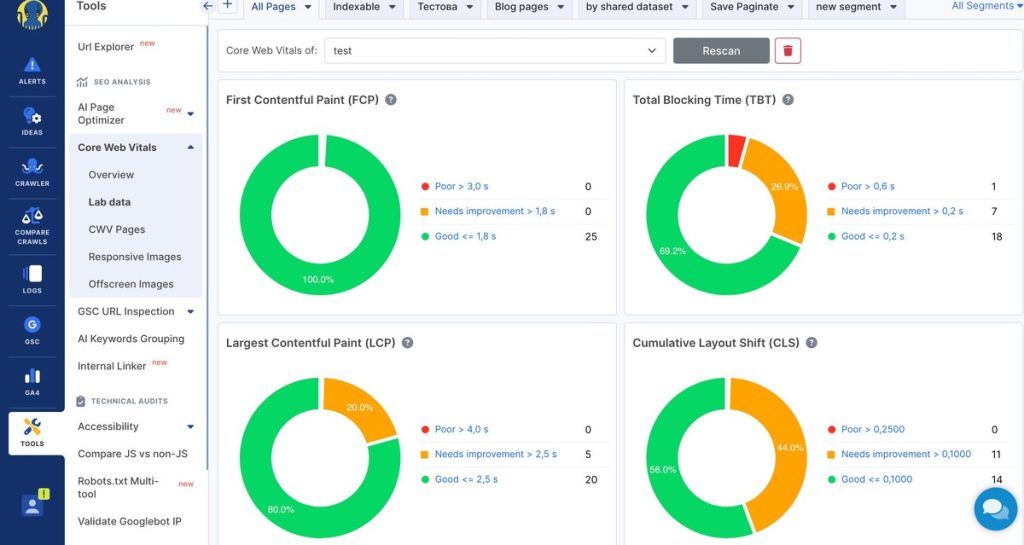
What is log file analysis and why do you need it
Log file analysis is the process that identifies technical issues by examining raw server logs to see exactly how search engine bots and users interact with your site. It gives you authoritative, first‑hand data on which pages are crawled, how frequently they’re accessed and where errors occur. Log files are extremely handy for your daily SEO routine as well as for more experimental tasks.
Most importantly, the data obtained from log file analysis provides a bulletproof argument that supports your SEO strategy and experiments. When you tell an engineering team that their JavaScript rendering pipeline is causing Googlebot to miss 30% of product pages, that claim lands very differently when it’s backed by six weeks of server logs showing exactly which URLs were requested, how many times and what response codes they received.
Furthermore, log files could be helpful for conversion optimization, showing which entry paths generate server-level signals worth investigating alongside your analytics data.
Caution! Log file analysis opens the black box. You’ll be amazed by the secrets your website holds, like crawl budgets consumed by URLs no one meant to keep, bots ignoring your most important pages, errors appearing and disappearing on schedules that never show up in manual testing.

What Log File Analysis Delivers for Your Business
Log analysis turns raw server data into quantifiable outcomes. These are the five metrics that directly connect crawl intelligence to revenue and operational performance.
| Business outcome | What Log Analysis Reveals | How It Moves the Metric | Who Owns the Fix |
|---|---|---|---|
| Indexed page count | Which pages Googlebot crawls vs. ignores and why | Eliminating crawl waste redirects bot capacity to pages that should be indexed but aren’t, directly growing index coverage | SEO+Engineering (crawl directives, redirect cleanup) |
| Organic traffic | High-value pages being under-crawled or returning intermittent errors | Fixing error patterns and crawl frequency gaps restores ranking signals on revenue-critical pages, recovering suppressed traffic | Engineering (server stability, 5xx resolution) |
| Crawl efficiency | What share of crawl budget lands on live, canonical, indexable pages | Removing redirect chains, parameter URLs and orphaned legacy pages raises the ratio of productive crawl visits – measurable within weeks | SEO (architecture) + Engineering (URL config) |
| Time-to-index | How long after publication before Googlebot first visits new content | Improving internal linking depth and DFI for new URLs accelerates first crawl – critical for news, product launches and time-sensitive content | SEO (internal linking strategy, sitemap hygiene) |
| Server cost & stability | Aggressive third-party and AI bots consuming disproportionate server resources | Identifying and rate-limiting wasteful bot traffic reduces unnecessary server load — a direct infrastructure saving with no SEO downside | Engineering (robots.txt, rate limiting, CDN config) |
1. Crawl Efficiency and Crawl Budget
What is Crawl Budget and Why Bother?
Crawl Budget is the number of pages Googlebot crawls and indexes on a website within a given period. Crawl capacity (server speed and stability) and crawl demand (page relevance and recency) jointly define the upper limit of how many pages search engines will crawl and index.
In other words, the crawl budget is the number of URLs Googlebot can and wants to scan. Yes, the crawl budget is limited and defined for each website individually. If your website has more pages than it’s set for crawling, Google will miss these extra pages. This, in turn, will affect your site’s performance in search results.
Google points to several major elements that can restrict a site’s ability to be properly crawled and indexed.
1. Session identifiers
2. On-site duplicate content
3. Soft error pages
4. Hacked pages
5. Infinite spaces and proxies
6. Low quality and spam content
Wasting server resources on pages like these will drain crawl activity from high-value pages, significantly delaying the discoverability of great content on the site.
Crawl Budget in the Era of AI Overviews
Traditional search crawlers now compete with AI crawlers for server capacity, bandwidth and processing time, creating new operational pressures for websites. AI bots generate high request volumes without guaranteeing proportional traffic, increasing infrastructure costs and forcing teams to rethink how crawl signals are prioritized.
Common issues for companies include:
- Bandwidth and cost spikes: AI crawlers can overwhelm CDNs, WAFs and hosting layers with high‑volume requests.
- Index bloat and wasted crawls: Low‑value or duplicate pages dilute crawl efficiency and slow recrawls of revenue‑driving content.
- Bot prioritization mismatch: AI crawlers often over‑crawl low‑value sections while under‑crawling critical, frequently updated pages.
But the good news is that the crawl budget can be extended. You can remove crawl waste, improve internal linking and clean up errors and technical issues – details discussed below.

Define Your Crawl Budget
The very first step in optimizing your crawl budget is checking the site’s crawlability. Let’s start with a quick, high-level overview in JetOctopus.
The ‘Log Overview’ tab provides you with the general crawl data:
- The Interactive Dynamics Of Bots Visits chart shows how often each bot visits your website and the number of pages it crawls each day (link)
- The Interactive Dynamics Of Subdomains chart demonstrates how subdomains are crawled.
Click on the Bot Dynamics tab for a more detailed review:
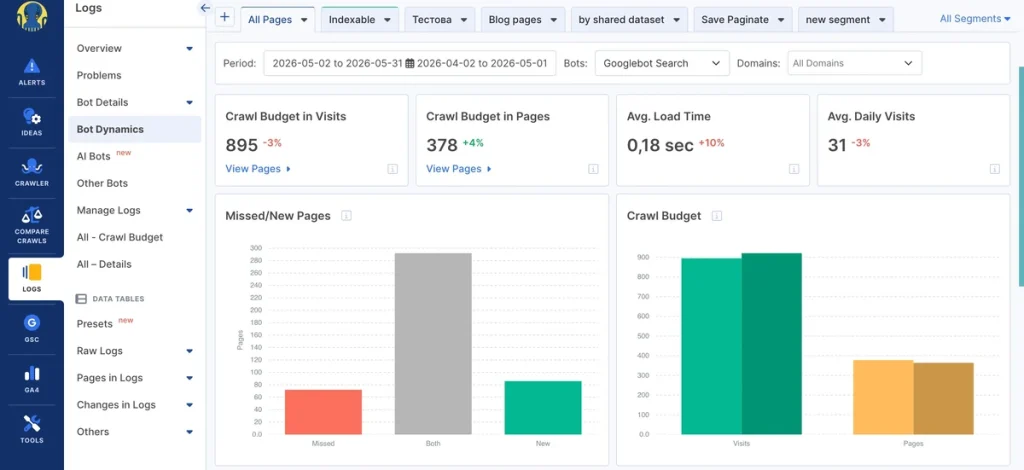
This dashboard showcases your crawl budget for each search bot. It can be extremely useful to quickly identify anomalies. You should check for deviations like spikes or declines.
However, the insights derived from this dashboard cannot be viewed independently. So, it’s time to go deeper for an eye-opening experience.
Here’s exactly how log file analysis helped these SEO specialists identify crawl budget:
When I performed my first log analysis with JetOctopus… I was shocked! I realized that Googlebot keeps attending hundreds of thousands of outdated, junk, and “gone forever” pages, even out of the Google index. They were consuming our website’s crawling budget dramatically. Another insight – now we know the minimum number of internal links that guarantee that your target page will be visited by Googlebot. And what’s exciting – there are dozens of new SEO insights ahead.
Dmytro Ternovyi, Senior SEO Specialist of Helfy
Log File analysis is a good way to better understand Google’s algorithms, including which pages are important (with intensive crawling and hundreds of hits per day) and which are not (with minimal crawling activity). It is also a great way to receive instant feedback from Google since when we analyze SERP positions, there is a huge delay between what was done and seeing the results of such. The biggest win for me has been optimizing my site’s structure after analyzing orphan pages and crawl depth, which has led to significant results.
Alex Buraks, Head of Growth at DiscoverCars.com
Identify Crawl Budget Waste
Crawl budget waste is a significant issue. Instead of valuable and profitable pages, Googlebot often crawls irrelevant and outdated pages.
Go to the ‘Impact HUB’ section to evaluate the Crawl Ratio and missed pages:
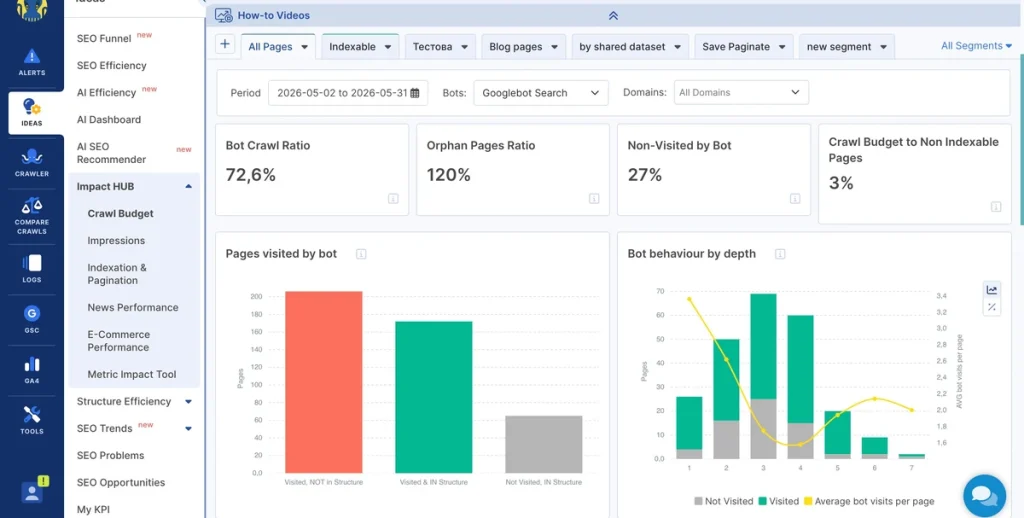
Once the crawl budget waste is obvious, it’s time for action. Each column is clickable and leads to the list of problematic URLs.
JetOctopus crawl data provides you with insights into what problems exist on these pages. This tells you what to change to get all your business pages visited by search bots.
Manage AI Crawl Budget
AI crawl budget is becoming just as critical as managing Googlebot’s.
With the Bot Dynamics report, you can track crawl frequency over time and pinpoint exactly when activity shifted, which sections were affected and what triggered it.
JetOctopus separates legitimate AI crawlers from fake ones using reverse DNS lookup, so you’re always working with reliable data. Each metric is drillable, leading directly to the URLs behind it.
Orphaned Pages
Orphaned pages are the pages that have no internal links pointing to them. They can be irrelevant, for example, inherent to previous site structures because search engines can’t reliably crawl them and users can’t easily find them. Also, these pages can have great potential, but it’s not visible due to low internal linking.
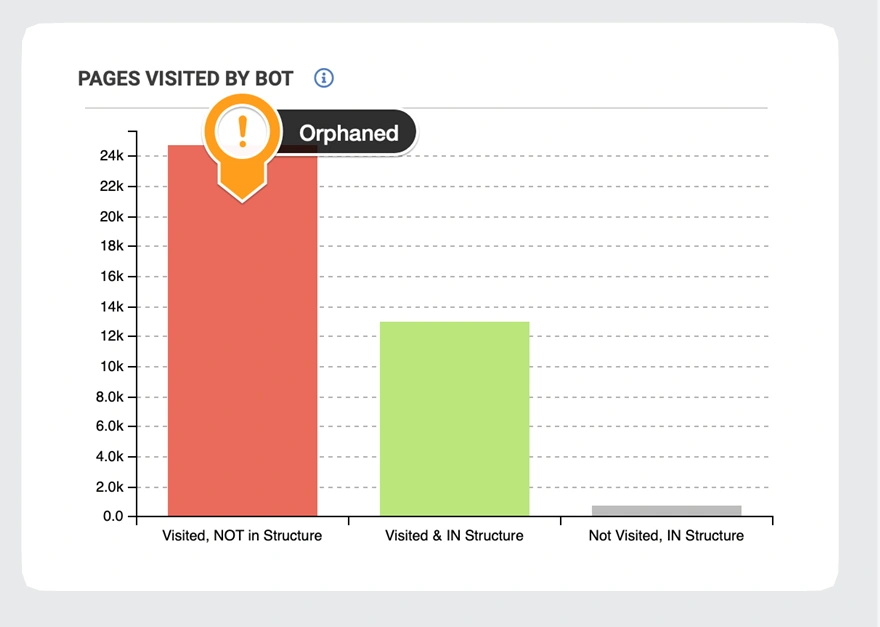
First and foremost, exclude irrelevant orphaned pages from crawling and indexation:
- Review these pages in detail
- Segment them by categories, directories or other meaningful groups
- Identify the areas with the most issues
- If some pages are valuable, reintegrate them into the site structure by adding internal links
- For low‑value or unnecessary pages, apply noindex and remove internal links or remove them from the website entirely
If these pages are orphaned by mistake, you should include them in the site structure. This would improve their performance.
AI bots are also known to crawl orphaned pages, especially if those URLs were ever referenced in indexed content or sitemaps.
What to do
Run a crawl in JetOctopus and cross-reference it with your log file data to surface pages that receive no internal links but are still being crawled.
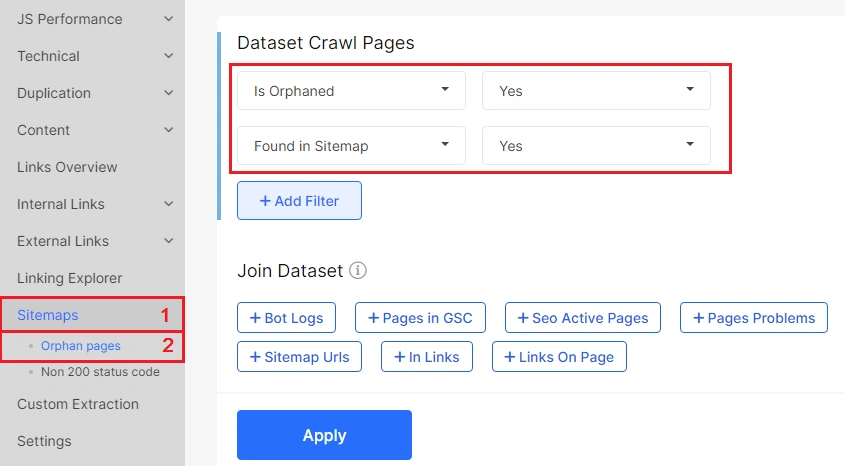
You’ll see which orphaned pages AI crawlers are accessing, helping you prioritize which ones to reintegrate or block. If an orphaned page is getting AI bot traffic but isn’t indexable or well-structured, it’s wasting AI crawl budget.
These clients used JetOctopus to discover orphaned pages:
Log analysis is one of the most important parts of the field of technical SEO. Don’t be afraid to jump into it! It allows you to have an exact and unlimited trace of the paths from robots. Some technical problems are only visible thanks to the logs, which makes the importance of an analysis primordial in a global SEO strategy.
The other great strength of the logs is to be able to cross this set of data with a crawl to easily and quickly identify orphaned URLs or hit pages that should not be. In constantly changing sites, the logs provide a historical trace of the evolution.
All this data allows you to demystify the notions of Crawl Budget and optimize the path of robots to important pages.
Pierrick Deniel, Head of Technical SEO at sortlist.com
Unlike the standard web crawlers and tools, Log files will tell you the full story. They can tell you how search engines are behaving on your site. Which pages they frequent, which pages they encounter problems with, how fast your server is responding, and many other essential things. Now, you take this information and overlay it on top of the web crawler data, and it will open up a whole different world. What if you can verify errors reported by a Web crawler? How about overlaying your website conversion data on top of the crawled URLs? How about seeing how a specific page is crawled over time by search engines as it goes through various updates? How about finding orphaned pages? You can do this a lot more accurately than using conventional methods. There are many use cases for log file analysis and it’s often more powerful when you combine it with a Web crawler.
Suganthan Mohanadasan, Co-founder and technical SEO lead at Snippet Digital
Not visited pages
Crawl budget waste inevitably results in some pages not being visited by Googlebot.
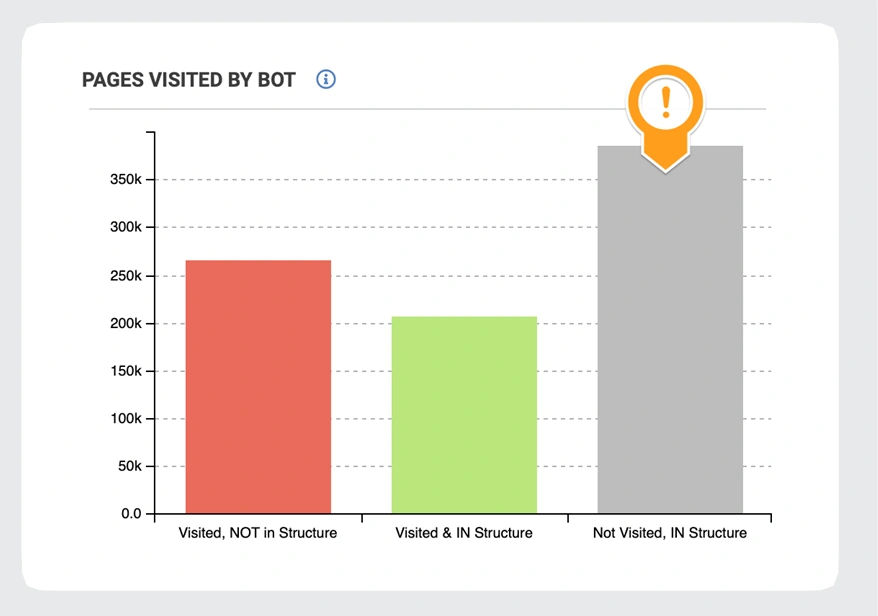
These pages could be ignored for a myriad of reasons, the most common ones being:
- Distance from index (DFI)
- Inlinks
- Content size
- Duplications
- Technical issues.
A closer look at crawl data will help you improve their crawlability, indexability and rankings.
For instance, here’s how TemplateMonster has handled both (orphan and not visited) types of pages.
What to do
Use JetOctopus and filter for pages that received zero Googlebot visits within your chosen time frame.
Get a clear overview of which pages are being ignored, how they’re distributed across your site structure and which underlying factors like depth, inlinks, content size, duplicates or technical issues are most likely responsible. You can prioritize fixes where they’ll have the most crawl budget impact.
Bot Behaviour by DFI (Distance from Index)
Distance from index (DFI) is equal to the clicks from the homepage to each page on the website. It’s an essential aspect that impacts the frequency of Googlebot’s visits.
You can access the dashboard from the ‘Impact HUB’ tab.
The following chart shows that if DFI is deeper than 4, Googlebot crawls only half of the web pages or even fewer. The percentage of processed pages reduces if the page is deeper:
Indeed, distance from the homepage is very important. Ideally, high-value pages should be 2-3 clicks away from your homepage. Anything that is 4 or more clicks away, will be seen by Googlebot as less important.
What to do
Check if these not-visited pages are valuable and profitable. If yes, improve their DFI by linking them from pages with smaller DFI.
Bot Behavior by Inlinks
Googlebot prioritizes pages that have lots of external and internal links pointing to them. This means that the number of inlinks is a significant factor impacting crawlability and rankings.
With JetOctopus data, you can optimize your interlinking structure and empower your most valuable pages.
You can find this chart on the Impact HUB page:
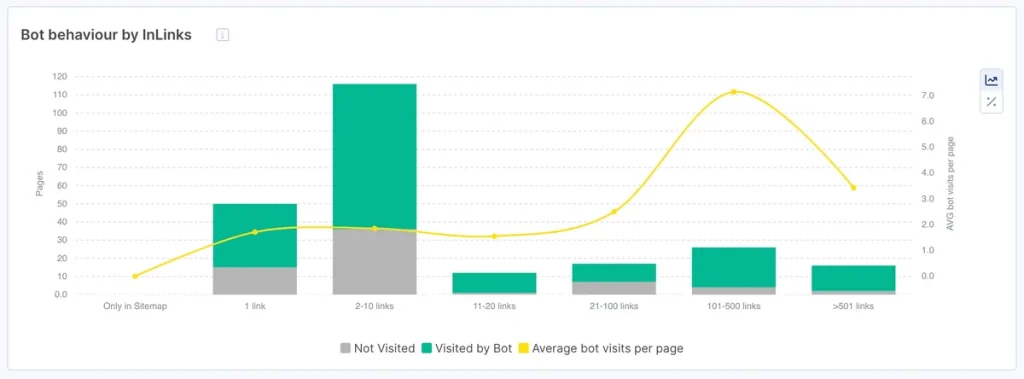
As you can see, there’s a correlation between the number of inlinks and crawled pages.
What to do
Firstly, check whether these not-visited pages are high-quality and profitable. If yes, increase the number of inlinks, especially from relevant pages with better crawl frequency.
Content Size
Content plays a significant role in SEO. Google’s algorithms are constantly evolving to deliver “…useful and relevant results in a fraction of a second.” The more relevant and engaging your content, the better your site’s performance.
This chart from the Impact tab demonstrates the correlation between content size and bot visits:
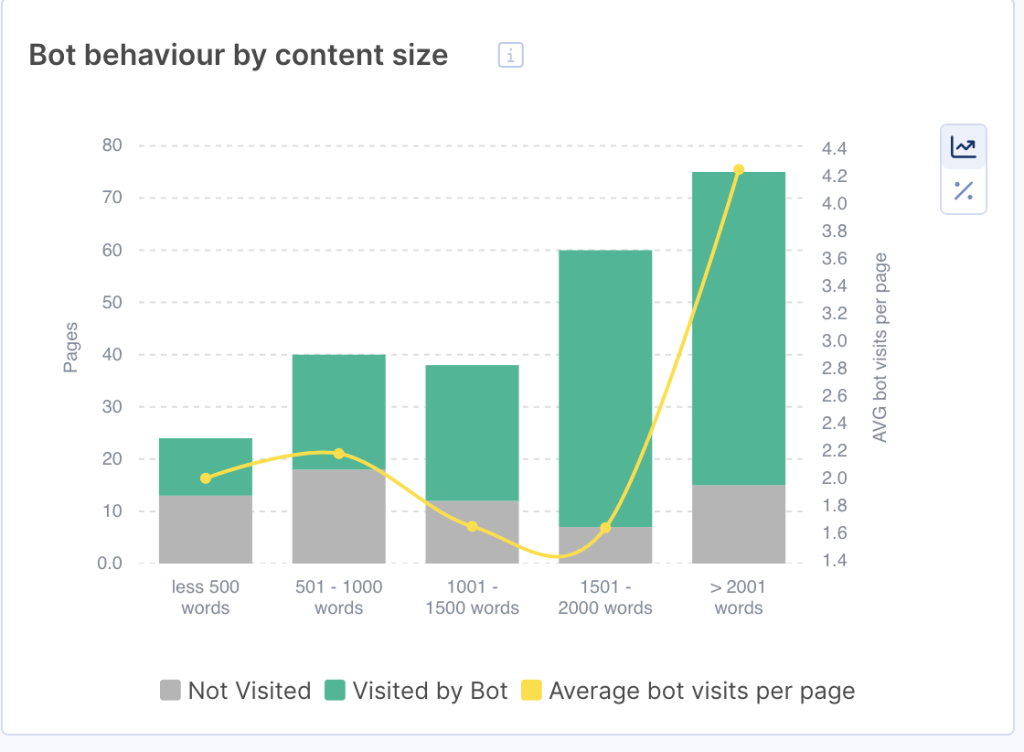
Pages with fewer than 500 words have the worst crawl ratio and are often considered low-quality pages.
Additionally, keep in mind that AI crawlers are specifically looking for content to train on or cite. Pages with thin content are less likely to be cited by ChatGPT, Perplexity or Claude.
What to do
Firstly, decide whether you need these pages. If yes, enhance the page content using Google’s Guidelines. Also, check how AI bots interact with your thin pages. JetOctopus shows the most visited pages by AI crawlers, so you can cross-reference whether your content-rich pages are the ones actually being retrieved or whether AI bots are spending their budget on low-value, shallow pages instead.
This client used JetOctopus to uncover interlinking inconsistencies and turned logs into a measurable success:
Log analysis has become a part of my SEO routine. It’s really helpful not only for regular health checks but also for more advanced tasks.
Log analysis showcases weak spots and provides useful insights. To me, the greatest challenge was a migration of a storied website with 300k+ indexed URLs and even more URLs inside the black box. With the log analysis, we discovered tons of orphaned pages, inconsistency in interlinking structure, and technical issues.
With this data, the migration became less challenging. We could successfully map all the required redirects, optimize the site’s structure, prevent migration of technical errors, and optimize the interlinking structure. Long story short: the migration proved to be successful and organic traffic increased.
Lena Bespalova, SEO Strategist at Covers
The same for this client, who realized how important log file analysis is when it comes to data quality:
Well, one thing that comes to my mind, hasn’t been covered that much and what many don’t necessarily understand is that the data in logs is exact. Not like in GA where blockers, the timing of the data push, sampling, etc. can affect the data. In most cases, logs are 100% accurate. So when you analyze the data it is trustworthy by default. Ofc it is also unfiltered by default so might need to clean it up a bit. Like internal traffic etc. But from that data whatever analysis you do after proper filtering is pretty much something you can be confident to make decisions on.
Aarne Salminen, SEO Strategist at Sanoma Media Finland
Title tag Issues
Titles are critical to giving users, search and AI bots a quick insight into the content and its relevance to the keyword. High-quality titles on your web pages ensure a healthy crawl rate, indexation and rankings.
There are two major crawlability issues associated with the title tags:
- Duplicated titles
- Empty titles.
These errors most likely cause insufficient crawlability. Check this chart on Bot Behaviour by Title Duplications:
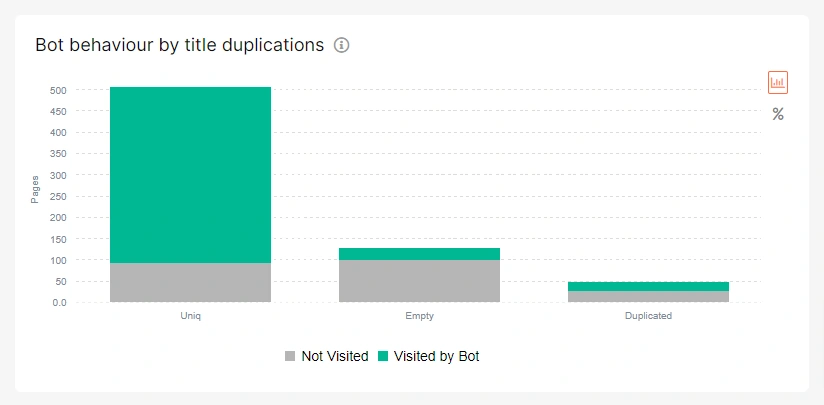
What to do
Firstly, decide whether you need these pages with empty or duplicate titles or not. And then optimize title tags using Google’s Guidelines, or remove unnecessary pages.
2. Indexation Control and Waste Prevention
Define the most visited pages
“URLs that are more popular on the Internet tend to be crawled more often to keep them fresher in our index.” – Google.
Pages that are most visited by Googlebot are considered as the most important ones. You should pay the closest attention to such URLs, keeping them evergreen and accessible. You can find the most visited URLs by clicking on charts in the ‘Pages by Bot Visits’ report:
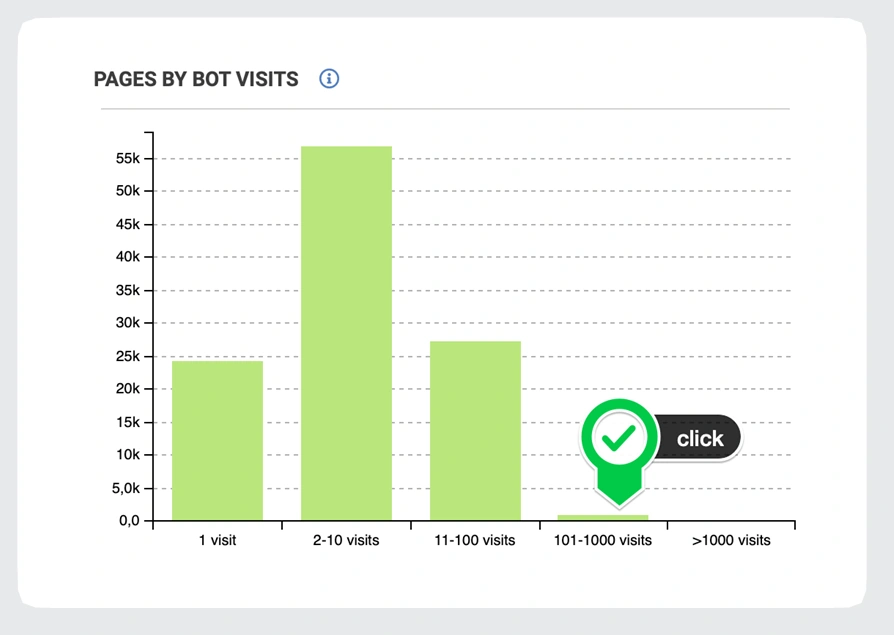
You can add links from these pages to the weaker ones (but relevant) to improve their crawlability and rankings.
Define the least visited pages
By clicking on ‘Pages by Bot Visits’ you can evaluate the least visited pages.
PRO-TIP
Even though the frequency of Googlebot’s visits doesn’t necessarily correlate with good rankings, it’s a good practice to check high-value pages among these pages with a couple of visits. You find that some of those pages are only getting crawled once or twice, that’s a sign to act. JetOctopus gives you the underlying data to understand why those pages are being crawled infrequently and you can build a concrete, evidence-based plan to fix those issues:
- Decrease the page’s DFI
- Revise interlinking
- Optimize the page’s content
What to do
Open the Bot Details report in JetOctopus and sort by lowest crawl frequency to identify high-value pages that Googlebot is visiting only once or twice.
You’ll get the underlying data to understand why each page is being crawled infrequently, whether it’s depth, weak interlinking or content issues, so you can build a concrete, prioritized plan to fix them.
Non-indexable pages with Googlebot’s visits
Googlebot visits non-indexable pages, such as:
- Non-200 status code pages
- Non-canonical pages
- Pages blocked in robots meta tag and X-Robots-Tag
To ensure Googlebot isn’t visiting non-indexable pages, go to the Impact Dashboard:
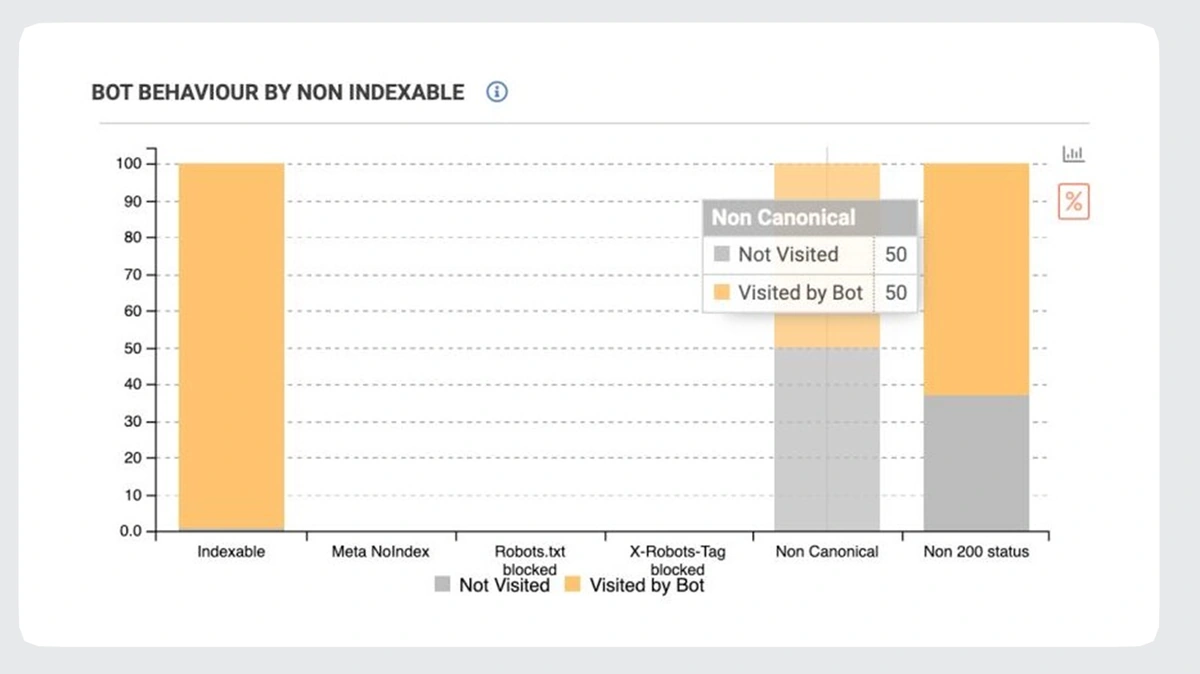
The most common reason for such pages being crawled is the internal links pointing to them. Or maybe, some other page points to the non-indexable ones as a canonical or alternative lang version (hreflang tags). This, in turn, causes crawl budget waste.
Plus, AI crawlers visit non-indexable pages through internal links like Googlebot and generate hallucinated URLs entirely independently.
JetOctopus catches both, letting you identify redirect opportunities and content gaps unique to AI bot behavior. Once you know which pages need better link equity, the AI Internal Linker helps you act on such issues directly by identifying where to add internal links to reintegrate underlinked pages into your site structure. Decide whether to allow, block or adjust directives with confidence and make sure AI crawlers are spending their budget on the pages that actually matter.
This testimonial backs this up:
The biggest challenge in log analysis is to understand how all this data is connected to your website. What does it all mean? Without it, you can’t make the right conclusion, and all the insights can be inaccurate.
I am glad that I can analyze millions of log data lines overlaying them with crawl for 3 Mln urls and GSC data for a month. Because it gives you really interesting data joins: how many noindex pages are crawled by Googlebot; what are the most effective pages by clicks in logs and a lot of other questions can be answered with the help of logs overlapped with other datasets.
My last colossal finding was a segment of the pages that got bot visits over the given period of time. We’ve found millions of trash pages crawled by Googlebot. We closed all these pages in robots.txt and saved the crawl budget for the profitable pages. I know that it will lead to better indexability shortly.
Ihor Bankovskyi, Senior Manager Global SEO at adidas.
What to do
Check and do your best so the non-indexable pages:
- Don’t have any inlinks
- Are non-canonical
- Are not used in hreflang tags
Here’s more on how to determine which pages bots visit or skip and the factors that influence their decisions.
Hreflang Issues
Hreflang attributes tell search engines that a website has localized versions of its pages, for example, separate English versions for the UK and the US. When implemented incorrectly, these tags cause search engines to serve the wrong page version to users, breaking international targeting and reducing visibility in the regions you’re trying to reach.
The most common hreflang errors to watch for:
- Relative URLs: hreflang must contain an absolute URL with HTTPS protocol and domain, or search engines won’t process it correctly
- Non-200 URLs: only URLs returning a 200 status code will be indexed from hreflang references
- Non-indexable URLs: hreflang and noindex are conflicting directives; search engines will apply the more restrictive rule (noindex), meaning your localized page won’t appear in search results
What to do
Run a sitemap scan in JetOctopus to surface all hreflang issues across your site at once. The Indexation Problems list flags pages with relative hreflang URLs, non-200 hreflang references and non-indexable hreflang targets, giving you a clear action list to work through.
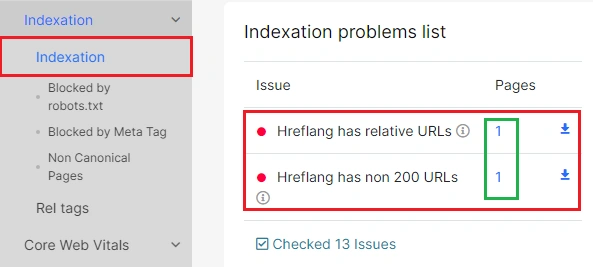
Fix each issue according to Google’s recommendations: use absolute URLs, ensure all hreflang targets return 200 responses and resolve any conflicts with noindex directives.
This ensures accurate regional and language targeting and protects your site’s visibility for international SEO.
3. Tech Health and Server Performance
HTTP status codes
HTTP status codes have the biggest impact on SEO. Make sure your crawl budget is not spent on 3xx-4xx pages and keep an eye on 5xx errors.
You can find the breakdown of status codes on the Bot Dynamics dashboard:
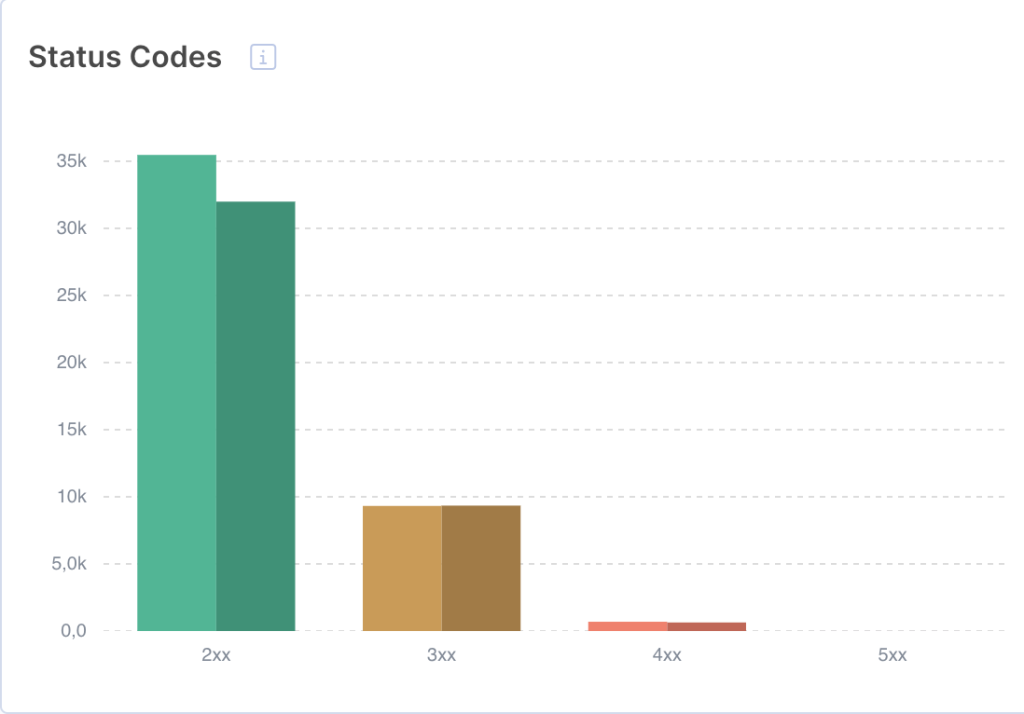
5xx Errors
500 server error and server response time are crucial because they affect access to your site. Search engine bots and human visitors alike will be lost. A significant number of 5xx errors or connection timeouts slows down the crawling.
You can quickly spot critical issues via the Health and Bot Dynamics Dashboards. If something goes wrong for Googlebot, you’ll be able to notice it in real-time and act accordingly.
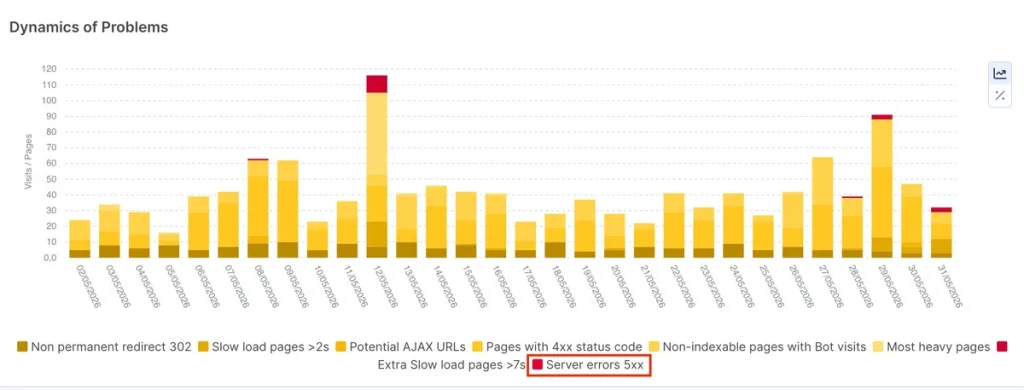
What to do
Investigate and fix those issues as soon as you encounter them. If those errors are frequent, consider optimizing your server’s capacity.
3xx Status Codes
3xx status codes are used for redirection. The most common are permanent redirects (301 status codes) and temporary redirects (302 and 307 status codes).
Bot Dynamics and Health dashboards contain such data:
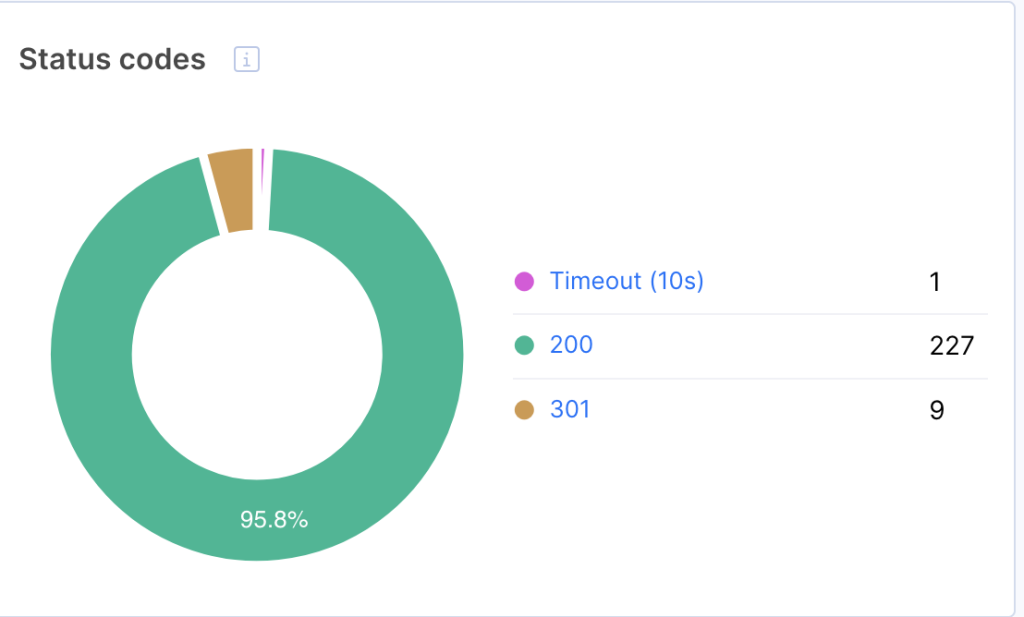
What to do
Investigate 3XXs. Why are they being crawled?
- Check internal links to these pages
- Check if they are used in canonical tags
- Check if they are used in hreflang tags
- Check if they are still included in XML Sitemaps
- Check chains of redirects
- Evaluate which part of crawl budget is wasted on redirections
This client used JetOctopus log file analyzer to filter navigation affects crawl budget, and whether 404 and 301 pages are handled correctly:
Doing SEO on the top level with large or huge websites without analyzing logs is just impossible.
For example, without logs on an e-commerce site you won’t be able to know:
which page type is most crawlable, which categories can cause problems, is your internal linking strategy correct, does your filter navigation work properly? Or some really basic stuff like if there are new problems after a recent dev release? Are you dealing with pages with 5XX status? Do you properly handle 404 and 301 pages?
Also, keep in mind that with tools like JetOctopus you can combine your logs with GSC or crawl data. Imagine you can easily see the correlation between content quality and crawl rate or from a business value perspective, the number of products in a specific category and crawl rate. By combining logs with custom extraction, the only thing that is limiting you is your own imagination.
Wojciech Krepa, SEO Consultant at Relevanto
And this is how an SEO specialist fixed critical server logs SEO and response issues at scale:
Crawl budget is one of the main components of effective website scanning. The garbage technical pages appear on websites quite often (especially on the old ones), and it’s difficult to identify those pages without proper analysis.
With the help of log analysis of our site, we have found tens of thousands of junk pages that should not have been visited by Googlebot. We have managed to significantly optimize the crawlability of important pages after we’ve worked with the website structure, tags, etc.
Log file analysis allowed us to identify many unacceptable server responses (503, 302 in particular), which were received by Googlebot in large numbers during the crawling process. These problems were solved on a server-side in a short time.
Having a lot of design templates on our site, the log analysis showed us a clear picture of the bots` behavior on pagination pages. Our goal is to index tens of thousands of such templates, hence analyzing logs is extremely insightful for our website.
Also, the log files allowed us to identify the pages most visited by bots. In one click, we received a huge amount of information and loaded the backlog for months ahead.
Serhii Voitekovych, Head of SEO at Depositphotos
4xx Status Codes
The most common 4XXs are:
- 404 Not Found – the file or page wasn’t found by the server. It doesn’t indicate whether it is missing permanently or only temporarily.
- 410 Gone – is more permanent than a 404; it means that the page is gone.
Google spends crawl budget on these pages:
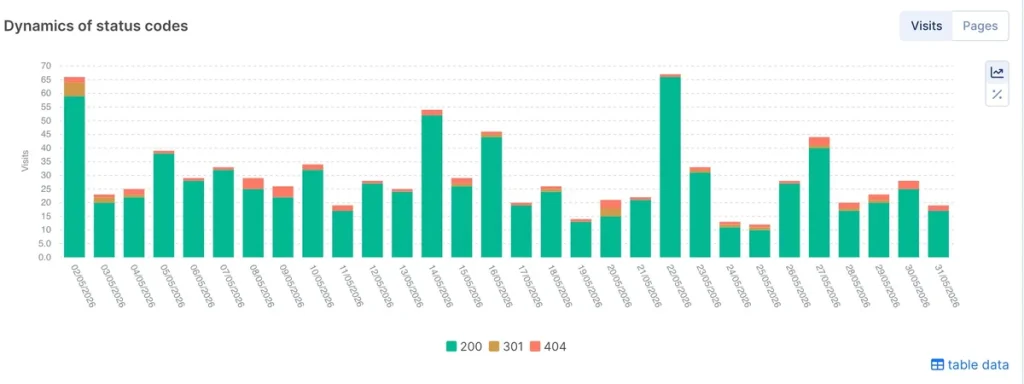
What to do
Investigate 4XXs. Why are they being crawled?
- Check internal links to these pages
- Check if they are canonical
- Check if they are used in hreflang tags
- Check if they are still included in XML Sitemaps
- Check if redirects point to 4xx pages
- Evaluate which part of crawl budget is wasted on them
If the pages returning 404 codes were high-authority pages with lots of traffic or Googlebot’s visits, you should employ 301 redirects to the most relevant page possible.
Here’s how a client solved their 404 issues:
It doesn’t matter how clever your internal linking system is – Google will always have its own view on how to crawl your website. Google’s behavior on different language versions of our website (which are almost identical) was surprisingly rather different.
Nowadays SEO requires you to push as many experiments as your dev team can. Even at the cost of extensive testing which sometimes leads to unexpected results.
With fast and highly customizable JetOctopus filtering and analytics tools, we were able to find errors and even whole problematic page clusters (50k+ 404 pages still under crawl).
Using the JetOctopus log analysis, we’ve reviewed our indexing policy. After about a year that helped us achieve 80–90% crawled pages by Google of all known, and the number of active pages increased by 60%.
Implementing improvements from JetOctopus reports on a regular basis, we have prevented a few (possibly big) indexing issues in our tests and now it is a vital part of our day-to-day routine.
Mikhail Bulanov, COO of tranio.com
Load time
Site speed significantly affects your crawl budget. For Googlebot, a speedy site is a sign of healthy servers, so it can get more content over the same number of connections.
Check HTML load time for search bots and their dynamics on Bots Dynamic dashboard:
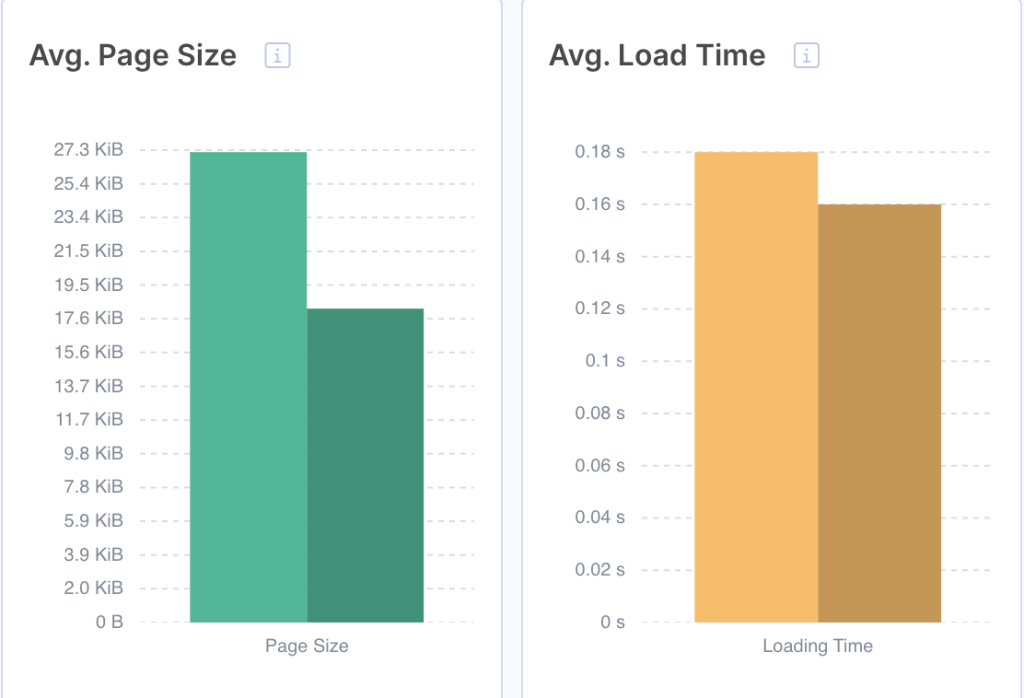
What to do
Improving site speed requires your development team, but start by identifying exactly what’s slow. Use JetOctopus to run bulk Core Web Vitals analysis across large URL sets, segment by page type to isolate underperforming groups and uncover blocked JavaScript or CSS files breaking render. Cross-reference Google Search Console’s Core Web Vitals report and PageSpeed Insights for actionable fixes, prioritizing LCP improvements on your highest-traffic pages first.
Mobile-First Indexing
Google switched to mobile-first indexing for all websites in September 2020. In the meantime, they continued moving sites to mobile-first indexing when their systems recognized that the site was ready.
If your website has not been switched to mobile-first indexing yet, keep an eye on Google’s mobile bot and its behavior.
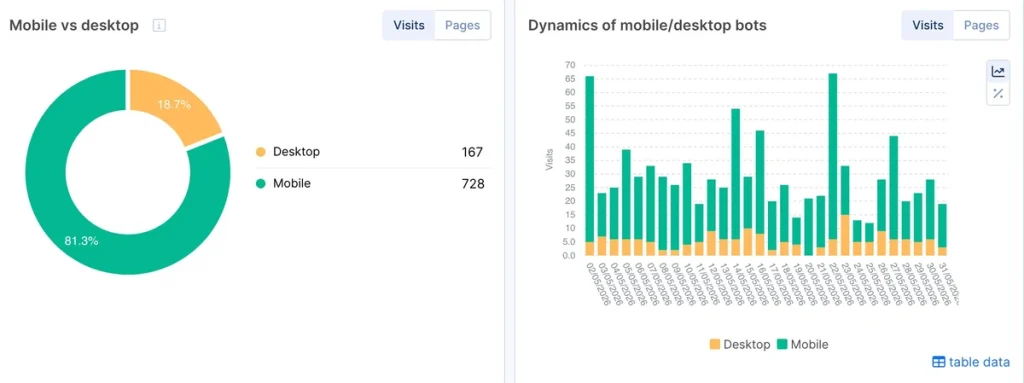
What to do
Make sure your website is mobile-friendly. Check Google’s Guidelines for mobile indexing.
JS Rendering Failures
Sometimes search engines can’t properly execute or process the JavaScript needed to display your page’s content. As a result, Googlebot and other crawlers see only partial content or nothing at all, even though the page loads fine for human visitors. For AI crawlers, the situation is even more critical; most AI bots don’t render JavaScript at all, meaning anything injected client‑side is completely invisible to them. For AI visibility, all essential content should be present in the initial HTML output.
The most common causes include critical content that loads only via JavaScript, rendering that takes too long, blocked JavaScript or CSS files or client-side rendering (CSR).
When any of these occur, Google may index incomplete or empty pages and URLs can be misclassified as soft 404s even though they work perfectly for real users. Since JavaScript‑injected content simply doesn’t exist for AI bots, making heavy CSR is one of the most damaging technical issues for AI visibility.
What to do
Run a JS crawl in JetOctopus to find content and internal linking gaps. Compare JS vs Non-JS Versions (critical for content gaps). This will show you what content was added and what content was removed after JS rendering and check if all links are visible in the rendered version.
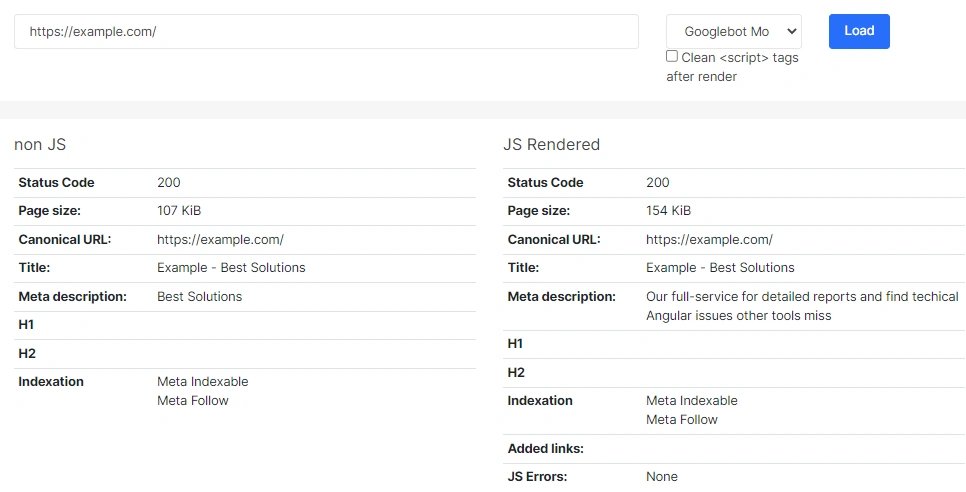
You’ll have a list of all the pages that are indexable, which meta tags Googlebot actually sees, which URLs are inaccessible to this user agent and where mobile and desktop versions diverge.
4. User Experience
A detailed log file analysis also showcases how organic visitors perceive your site and the technical issues they are facing. This section is especially important for optimizing conversions.
1. Evaluate how organic visitors explore your website. Refer to this bar chart in JetOctopus’ log file analyzer.
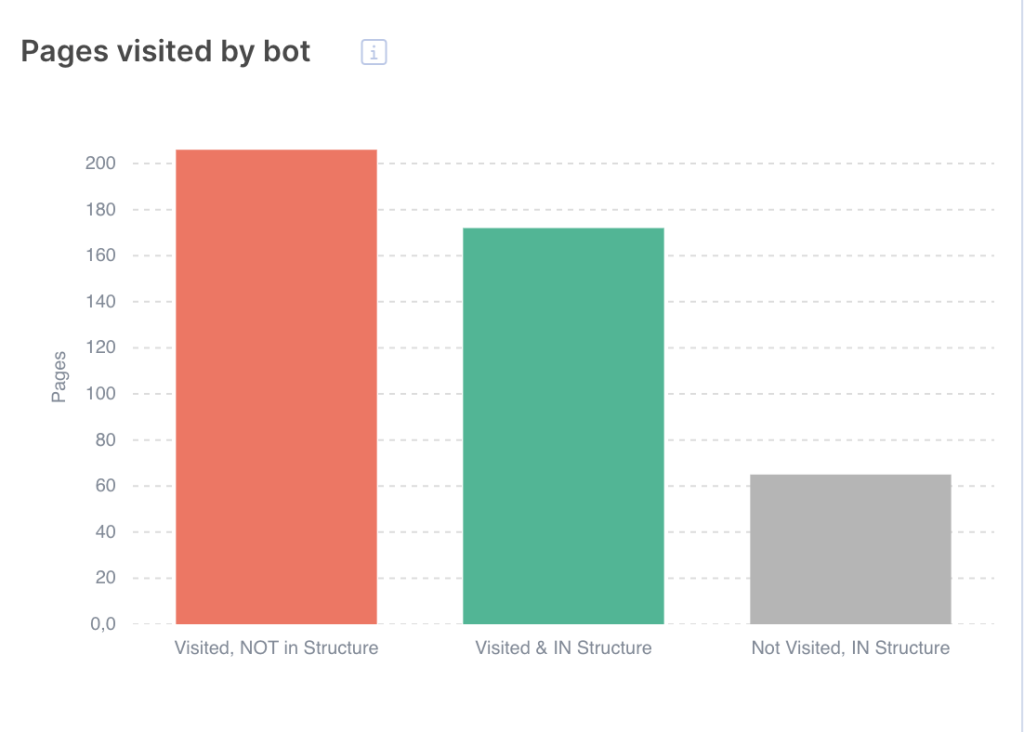
- The red bar represents the orphaned pages visited by organic users. By including these pages into the site’s structure, you can improve their rankings and receive even more organic visitors.
- The grey bar demonstrates the pages within your site structure that had no organic visitors. You should revise these pages and devise a strategy for the said pages to improve their SEO performance.
2. Identify technical issues encountered by your visitors:

By resolving these errors, your site’s user experience will improve, thus increasing your conversion rates.
5. SEO and AI Efficiency
JetOctopus offers critical data on a site’s SEO efficiency through charts that connect three datasets, namely logs, crawl data and GSC data. This shows how efficient your site is in terms of SEO and whether the crawl budget is being spent optimally.
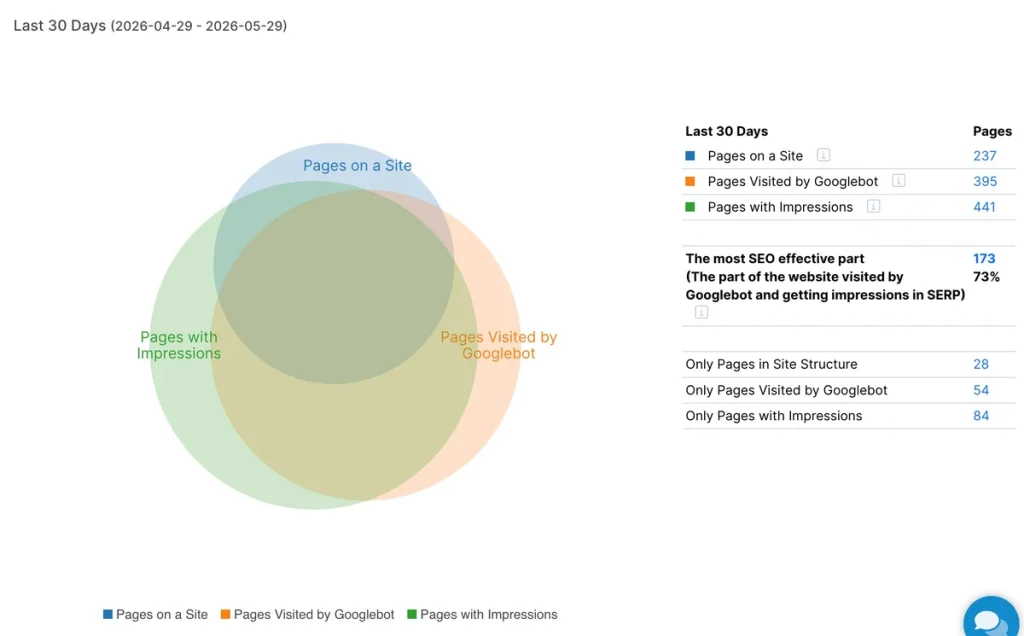
Thus, by integrating these three datasets, you can analyze the pages visited by search bots, the pages in the site structure and the pages getting impressions.
Here are a few log analysis SEO insights you can check for optimizing your pages.
- Crawl budget waste – This is the orange part of the circle that doesn’t overlap with the blue circle. These pages are visited by bots but are not present in the site structure. Hence, they are potentially wasting your crawl budget. You can either remove these pages or add them to your site structure.
- The invisible part of your website – This is the blue circle that doesn’t overlap with the orange circle. These are the pages visited by the bots but aren’t present in your site structure.
The pages visited by bots but aren’t getting impressions – The intersecting section between the orange and blue circles shows the pages that are visited by bots and in the site structure but aren’t getting impressions.
AI Bot Visibility
You can also track how AI bots (ChatGPT, Claude and Perplexity) crawl and interact with your site. With the AI Efficiency Report, you gain visibility into a layer of traffic that standard log analysis doesn’t surface on its own.
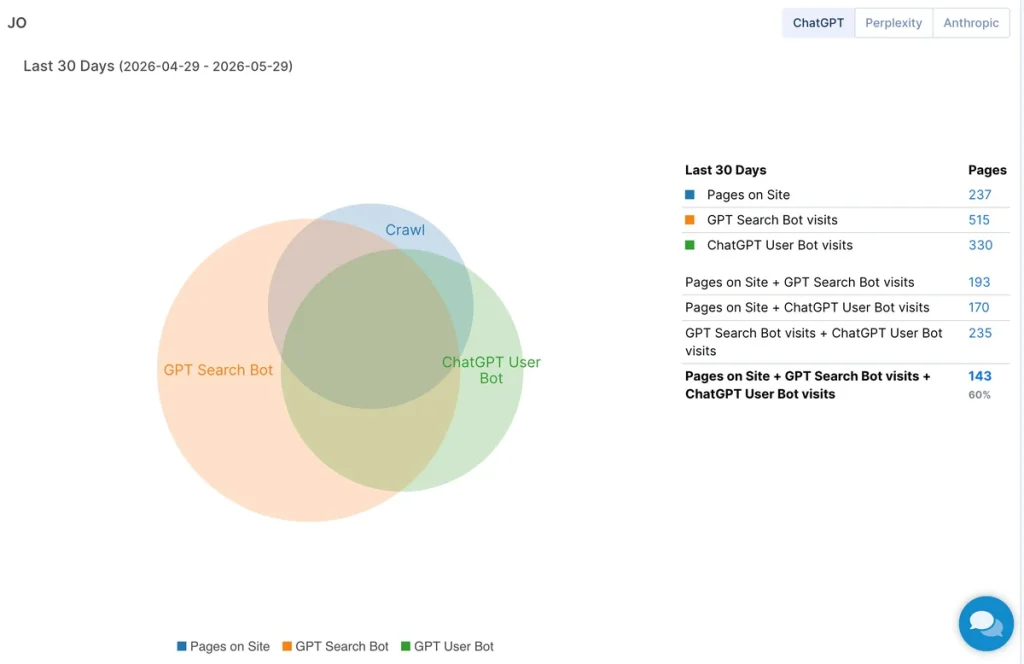
Specifically, you can identify which pages AI crawlers access, how their behavior differs from traditional search bots and where rendering or content gaps may be limiting your visibility in AI-generated answers.
Here are the key insights you can act on:
- AI bot activity: tracks crawl frequency and page-level behavior for each AI bot, showing which parts of your site they prioritize and which they ignore.
- AI vs. Googlebot comparison: highlights differences in what AI crawlers and Googlebot actually see, making rendering gaps and content discrepancies easier to identify and fix.
- Access control: surfaces pages receiving unwanted AI bot traffic, giving you the data to make informed robots.txt decisions without blocking valuable visibility.
Unified alerts: notifies you when AI bot activity shifts significantly, so you can investigate and respond before it affects your presence in AI-driven search results.
How to Prioritize Fixes
| Issue Type | Impact on Crawl | Impact on Indexation | Business Impact |
|---|---|---|---|
| 5xx errors | High | High | High |
| Orphan pages | Medium | High | Medium |
| Thin content | Low | Medium | Medium |
| Duplicate titles | Low | Low | Low |
Conclusion:
To sum up, log file analyzer is a must-have tool to boost your site’s crawlability, indexability and rankings.
In combination with crawl data and Google Search Console data, log file analysis will give you powerful insights to increase your organic traffic and conversions.
The in-depth file analysis using the JetOctopus Log tool, you’d be able to:
- Optimize crawl budget for Googlebot and AI bots
- Eliminate orphaned, thin and duplicate-content pages
- Resolve hreflang, JS rendering and HTTP status code issues
- Improve site structure, internal linking and page depth
- Monitor server logs, SEO health and spot errors before they affect rankings
When the data is this clear, every fix you make is one you can prove.
Choose the way of log file integration: 3 ways of log file integration with JetOctopus.

















